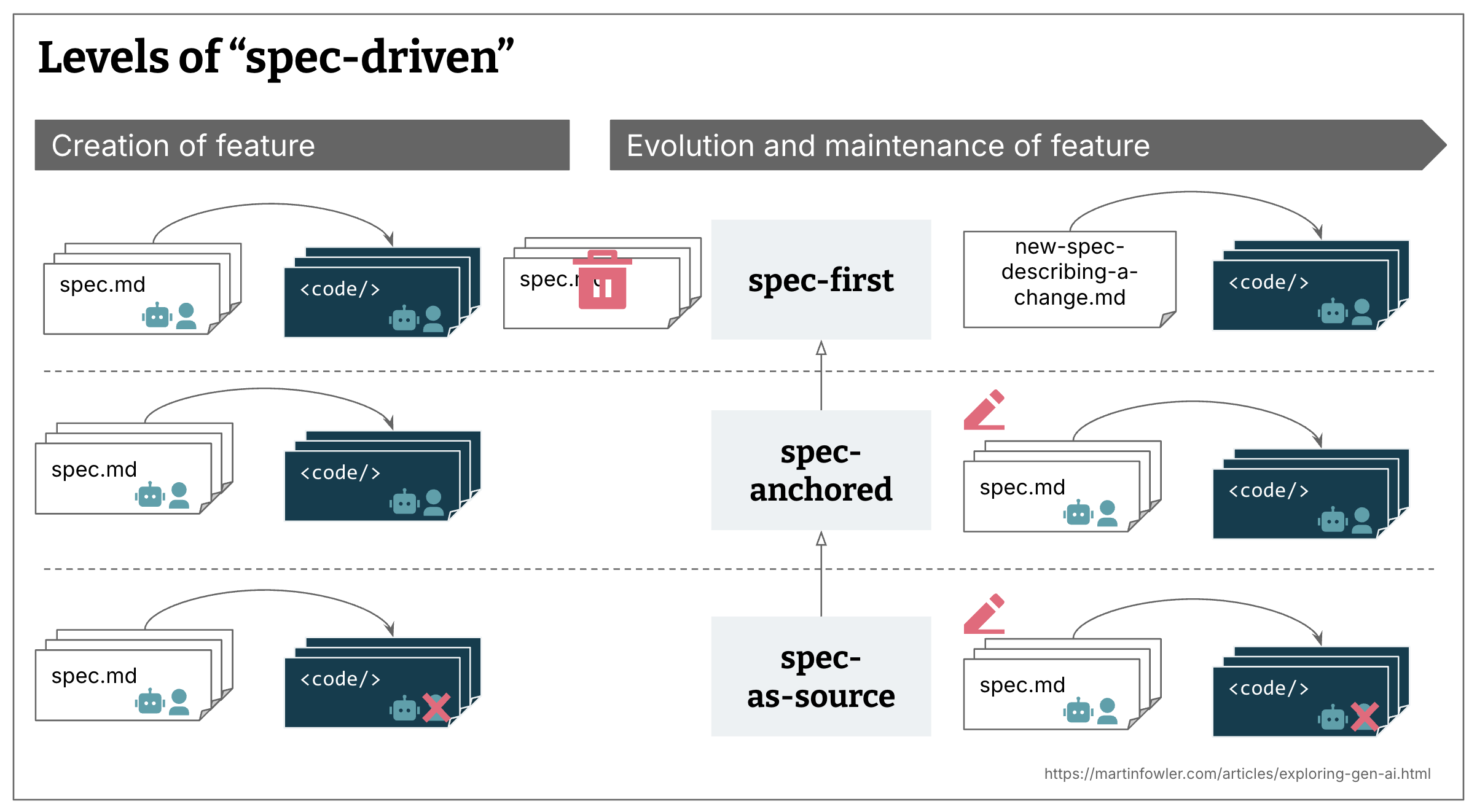
An illustration of the three observed levels of SDD, in 2 columns of “Creation of feature” and “Evolution and maintenance of feature”, each level shown in a row. Spec-first: Spec documents lead to code, both specs and code are marked with a robot and human icon, to show that both AI and humans are editing specs and code. Then after creation of feature, the specs are deleted, and during evolution a new spec is created that describes the change. Next row is spec-anchored, shows the same as spec-first, but the spec is not deleted after creation, instead it gets edited during evolution. Final row is spec-as-source, same as spec-anchored, but the human icon is crossed out for the code files, because humans here do not edit the code. All three concepts are connected with inheritance arrows (arrow with a head that is not filled with color), because they build up on top of each other. (View Highlight)
An overview diagram showing agent context files in two categories: Memory Bank (AGENTS.md, project.md, architecture.md as examples), and Specs (Story-324.md, product-search.md, a folder feature-x with files like data-model.md, plan.md as example files). (View Highlight)
I’ve been trying to understand one of the latest AI coding buzzword: Spec-driven development (SDD). I looked at three of the tools that label themselves as SDD tools and tried to untangle what it means, as of now. (View Highlight)
Like with many emerging terms in this fast-paced space, the definition of “spec-driven development” (SDD) is still in flux. Here’s what I can gather from how I have seen it used so far: Spec-driven development means writing a “spec” before writing code with AI (“documentation first”). The spec becomes the source of truth for the human and the AI. (View Highlight)
“In this new world, maintaining software means evolving specifications. […] The lingua franca of development moves to a higher level, and code is the last-mile approach.” (View Highlight)
“A development approach where specs — not code — are the primary artifact. Specs describe intent in structured, testable language, and agents generate code to match them.” (View Highlight)
After looking over the usages of the term, and some of the tools that claim to be implementing SDD, it seems to me that in reality, there are multiple implementation levels to it:
Spec-first: A well thought-out spec is written first, and then used in the AI-assisted development workflow for the task at hand.
Spec-anchored: The spec is kept even after the task is complete, to continue using it for evolution and maintenance of the respective feature.
Spec-as-source: The spec is the main source file over time, and only the spec is edited by the human, the human never touches the code.
All SDD approaches and definitions I’ve found are spec-first, but not all strive to be spec-anchored or spec-as-source. And often it’s left vague or totally open what the spec maintenance strategy over time is meant to be. (View Highlight)
The key question in terms of definitions of course is: What is a spec? There doesn’t seem to be a general definition, the closest I’ve seen to a consistent definition is the comparison of a spec to a “Product Requirements Document”. (View Highlight)
A spec is a structured, behavior-oriented artifact - or a set of related artifacts - written in natural language that expresses software functionality and serves as guidance to AI coding agents. Each variant of spec-driven development defines their approach to a spec’s structure, level of detail, and how these artifacts are organized within a project. (View Highlight)
There is a useful difference to be made I think between specs and the more general context documents for a codebase. That general context are things like rules files, or high level descriptions of the product and the codebase. Some tools call this context a memory bank, so that’s what I will use here. These files are relevant across all AI coding sessions in the codebase, whereas specs only relevant to the tasks that actually create or change that particular functionality. (View Highlight)
It turns out to be quite time-consuming to evaluate SDD tools and approaches in a way that gets close to real usage. You would have to try them out with different sizes of problems, greenfield, brownfield, and really take the time to review and revise the intermediate artifacts with more than just a cursory glance. Because as GitHub’s blog post about spec-kit says: “Crucially, your role isn’t just to steer. It’s to verify. At each phase, you reflect and refine.” (View Highlight)
For two of the three tools I tried it also seems to be even more work to introduce them into an existing codebase, therefore making it even harder to evaluate their usefulness for brownfield codebases. Until I hear usage reports from people using them for a period of time on a “real” codebase, I still have a lot of open questions about how this works in real life. (View Highlight)
That being said - let’s get into three of these tools. I will share a description of how they work first (or rather how I think they work), and will keep my observations and questions for the end. Note that these tools are very fast evolving, so they might have already changed since I used them in September. (View Highlight)
Kiro is the simplest (or most lightweight) one of the three I tried. It seems to be mostly spec-first, all the examples I have found use it for a task, or a user story, with no mention of how to use the requirements document in a spec-anchored way over time, across multiple tasks. (View Highlight)
Requirements → Design → Tasks
Each workflow step is represented by one markdown document, and Kiro guides you through those 3 workflow steps inside of its VS Code based distribution.
Requirements: Structured as a list of requirements, where each requirement represents a “User Story” (in “As a…” format) with acceptance criteria (in “GIVEN… WHEN… THEN…” format) (View Highlight)
Tasks: A list of tasks that trace back to the requirement numbers, and that get some extra UI elements to run tasks one by one, and review changes per task.
Kiro also has the concept of a memory bank, they call it “steering”. Its contents are flexible, and their workflow doesn’t seem to rely on any specific files being there (I made my usage attempts before I even discovered the steering section). The default topology created by Kiro when you ask it to generate steering documents is product.md, structure.md, tech.md. (View Highlight)
Spec-kit is GitHub’s version of SDD. It is distributed as a CLI that can create workspace setups for a wide range of common coding assistants. Once that structure is set up, you interact with spec-kit via slash commands in your coding assistant. Because all of its artifacts are put right into your workspace, this is the most customizable one of the three tools discussed here (View Highlight)
Spec-kit’s memory bank concept is a prerequisite for the spec-driven approach. They call it a constitution. The constitution is supposed to contain the high level principles that are “immutable” and should always be applied, to every change. It’s basically a very powerful rules file that is heavily used by the workflow. (View Highlight)
In each of the workflow steps (specify, plan, tasks), spec-kit instantiates a set of files and prompts with the help of a bash script and some templates. The workflow then makes heavy use of checklists inside of the files, to track necessary user clarifications, constitution violations, research tasks, etc. They are like a “definition of done” for each workflow step (though interpreted by AI, so there is no 100% guarantee that they will be respected). (View Highlight)
At first glance, GitHub seems to be aspiring to a spec-anchored approach (“That’s why we’re rethinking specifications — not as static documents, but as living, executable artifacts that evolve with the project. Specs become the shared source of truth. When something doesn’t make sense, you go back to the spec; when a project grows complex, you refine it; when tasks feel too large, you break them down.”) However, spec-kit creates a branch for every spec that gets created, which seems to indicate that they see a spec as a living artifact for the lifetime of a change request, not the lifetime of a feature. This community discussion is talking about this confusion. It makes me think that spec-kit is still what I would call spec-first only, not spec-anchored over time. (View Highlight)
Tessl Framework
(Still in private beta)
Like spec-kit, the Tessl Framework is distributed as a CLI that can create all the workspace and config structure for a variety of coding assistants. The CLI command also doubles as an MCP server. (View Highlight)
essl is the only one of these three tools that explicitly aspires to a spec-anchored approach, and is even exploring the spec-as-source level of SDD. A Tessl spec can serve as the main artifact that is being maintained and edited, with the code even marked with a comment at the top saying // GENERATED FROM SPEC - DO NOT EDIT. This is currently a 1:1 mapping between spec and code files, i.e. one spec translates into one file in the codebase. But Tessl is still in beta and they are experimenting with different versions of this, so I can imagine that this approach could also be taken on a level where one spec maps to a code component with multiple files. It remains to be seen what the alpha product will support. (The Tessl team themselves see their framework as something that is more in the future than their current public product, the Tessl Registry.) (View Highlight)
ags like @generate or @test seem to tell Tessl what to generate. The API section shows the idea of defining at least the interfaces that get exposed to other parts of the codebase in the spec, presumably to make sure that these more crucial parts of the generated component are fully under the control of the maintainer. Running tessl build for this spec generates the corresponding JavaScript code file. (View Highlight)
Kiro and spec-kit provide one opinionated workflow each, but I’m quite sure that neither of them is suitable for the majority of real life coding problems. In particular, it’s not quite clear to me how they would cater to enough different problem sizes to be generally applicable. (View Highlight)
When I asked Kiro to fix a small bug (it was the same one I used in the past to try Codex), it quickly became clear that the workflow was like using a sledgehammer to crack a nut. The requirements document turned this small bug into 4 “user stories” with a total of 16 acceptance criteria, including gems like “User story: As a developer, I want the transformation function to handle edge cases gracefully, so that the system remains robust when new category formats are introduced.” (View Highlight)
I had a similar challenge when I used spec-kit, I wasn’t quite sure what size of problem to use it for. Available tutorials are usually based on creating an application from scratch, because that’s easiest for a tutorial. One of the use cases I ended up trying was a feature that would be a 3-5 point story on one of my past teams. The feature depended on a lot of code that was already there, it was supposed to build an overview modal that summarised a bunch of data from an existing dashboard. With the amount of steps spec-kit took, and the amount of markdown files it created for me to review, this again felt like overkill for the size of the problem. It was a bigger problem than the one I used with Kiro, but also a much more elaborate workflow. I never even finished the full implementation, but I think in the same time it took me to run and review the spec-kit results I could have implemented the feature with “plain” AI-assisted coding, and I would have felt much more in control. (View Highlight)
As just mentioned, and as you can see in the description of the tool above, spec-kit created a LOT of markdown files for me to review. They were repetitive, both with each other, and with the code that already existed. Some contained code already. Overall they were just very verbose and tedious to review. In Kiro it was a little easier, as you only get 3 files, and it’s more intuitive to understand the mental model of “requirements > design > tasks”. However, as mentioned, Kiro also was way too verbose for the small bug I was asking it to fix. (View Highlight)
Even with all of these files and templates and prompts and workflows and checklists, I frequently saw the agent ultimately not follow all the instructions. Yes, the context windows are now larger, which is often mentioned as one of the enablers of spec-driven development. But just because the windows are larger, doesn’t mean that AI will properly pick up on everything that’s in there. (View Highlight)
It is a common idea in SDD to be intentional about the separation between functional spec and technical implementation. The underlying aspiration I guess is that ultimately, we could have AI fill in all the solutioning and details, and switch to different tech stacks with the same spec. (View Highlight)
Who is the target user?
Many of the demos and tutorials for spec-driven development tools include things like defining product and feature goals, they even incorporate terms like “user story”. The idea here might be to use AI as an enabler for cross-skilling, and have developers participate more heavily in requirements analysis? Or have developers pair with product people when they work on this workflow? None of this is made explicit though, it’s presented as a given that a developer would do all this analysis. (View Highlight)
In which case I would ask myself again, what problem size and type is SDD meant for? Probably not for large features that are still very unclear, as surely that would require more specialist product and requirements skills, and lots of other steps like research and stakeholder involvement? (View Highlight)
While many people draw analogies between SDD and TDD or BDD, I think another important parallel to look at for spec-as-source in particular is MDD (model-driven development). I worked on a few projects at the beginning of my career that heavily used MDD, and I kept being reminded about that when I was trying out the Tessl Framework. The models in MDD were basically the specs, albeit not in natural language, but expressed in e.g. custom UML or a textual DSL. We built custom code generators to turn those specs into code. (View Highlight)
Ultimately, MDD never took off for business applications, it sits at an awkward abstraction level and just creates too much overhead and constraints. But LLMs take some of the overhead and constraints of MDD away, so there is a new hope that we can now finally focus on writing specs and just generate code from them. With LLMs, we are not constrained by a predefined and parseable spec language anymore, and we don’t have to build elaborate code generators. The price for that is LLMs’ non-determinism of course. And the parseable structure also had upsides that we’re losing now: We could provide the spec author with a lot of tool support to write valid, complete and consistent specs. I wonder if spec-as-source, and even spec-anchoring, might end up with the downsides of both MDD and LLMs: Inflexibility and non-determinism. (View Highlight)
In my personal usage of AI-assisted coding, I also often spend time on carefully crafting some form of spec first to give to the coding agent. So the general principle of spec-first is definitely valuable in many situations, and the different approaches of how to structure that spec are very sought after. They are among the top most frequently asked questions I hear at the moment from practitioners: “How do I structure my memory bank?”, “How do I write a good specification and design document for AI?”. (View Highlight)
 An illustration of the three observed levels of SDD, in 2 columns of “Creation of feature” and “Evolution and maintenance of feature”, each level shown in a row. Spec-first: Spec documents lead to code, both specs and code are marked with a robot and human icon, to show that both AI and humans are editing specs and code. Then after creation of feature, the specs are deleted, and during evolution a new spec is created that describes the change. Next row is spec-anchored, shows the same as spec-first, but the spec is not deleted after creation, instead it gets edited during evolution. Final row is spec-as-source, same as spec-anchored, but the human icon is crossed out for the code files, because humans here do not edit the code. All three concepts are connected with inheritance arrows (arrow with a head that is not filled with color), because they build up on top of each other. (View Highlight)
An illustration of the three observed levels of SDD, in 2 columns of “Creation of feature” and “Evolution and maintenance of feature”, each level shown in a row. Spec-first: Spec documents lead to code, both specs and code are marked with a robot and human icon, to show that both AI and humans are editing specs and code. Then after creation of feature, the specs are deleted, and during evolution a new spec is created that describes the change. Next row is spec-anchored, shows the same as spec-first, but the spec is not deleted after creation, instead it gets edited during evolution. Final row is spec-as-source, same as spec-anchored, but the human icon is crossed out for the code files, because humans here do not edit the code. All three concepts are connected with inheritance arrows (arrow with a head that is not filled with color), because they build up on top of each other. (View Highlight)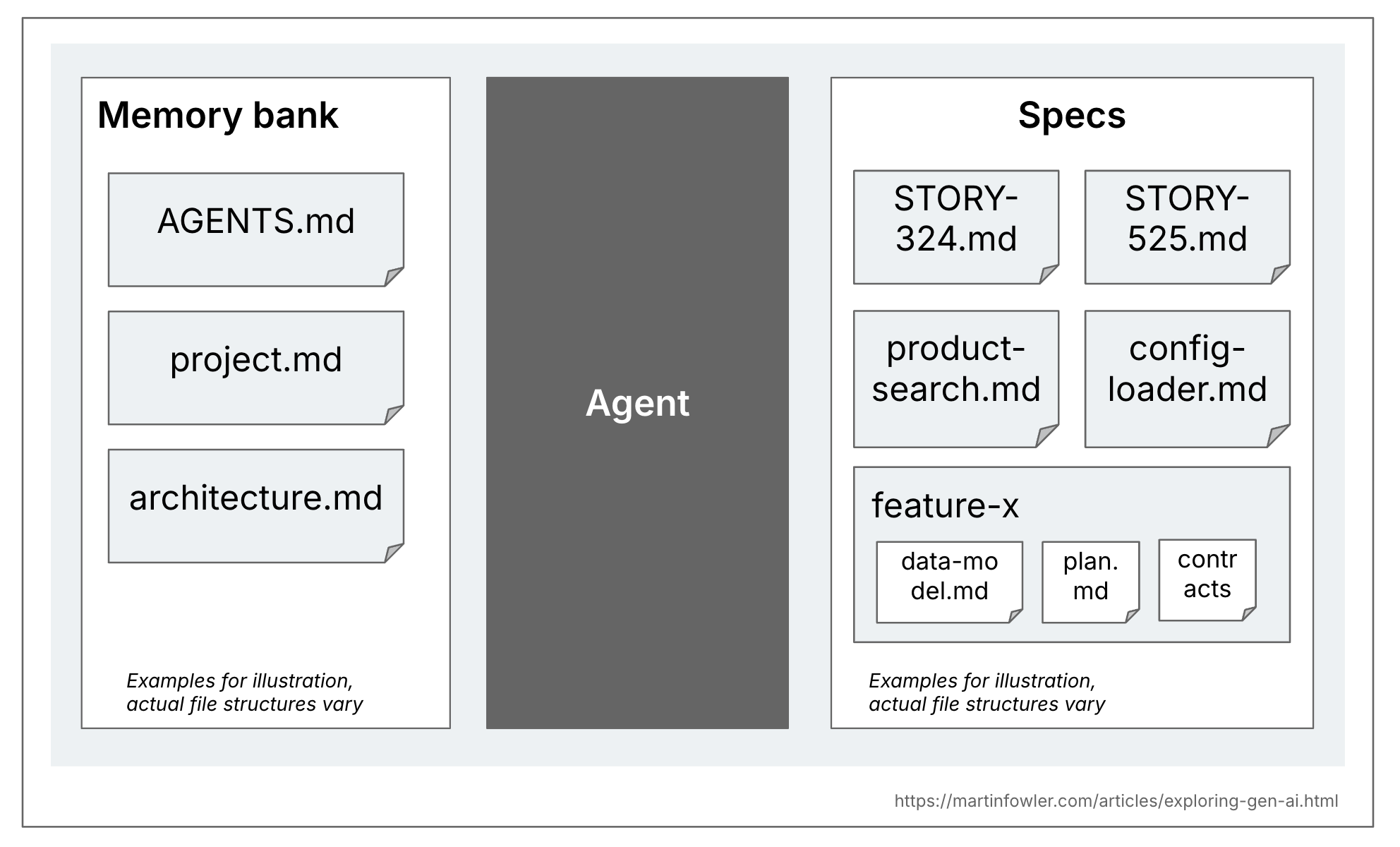 An overview diagram showing agent context files in two categories: Memory Bank (AGENTS.md, project.md, architecture.md as examples), and Specs (Story-324.md, product-search.md, a folder feature-x with files like data-model.md, plan.md as example files). (View Highlight)
An overview diagram showing agent context files in two categories: Memory Bank (AGENTS.md, project.md, architecture.md as examples), and Specs (Story-324.md, product-search.md, a folder feature-x with files like data-model.md, plan.md as example files). (View Highlight)