
Context Engineering is one of the newest buzzwords in AI, and I hope it doesn’t become another short-lived job title like “Prompt Engineer.” New tools and processes often require new skills, but in tech we sometimes rush to create roles that are either too broad (think Data Scientist) or too narrow (RAG Engineer).
I don’t want yet another job description. Still, Context Engineering is a skill you should learn if you want to use AI effectively. Have you ever dumped a folder into ChatGPT and hoped for the best? If you’ve used chatbots or coding agents, you know this: the better the information you give an AI, the better the results.
Let’s be clear: for an LLM, context is any piece of information available to the model that helps it achieve the user’s intent. That’s a broad definition, it goes beyond the prompt and can include almost anything. For a useful exhaustive explanation, see Philipp Schmid’s diagram and post.
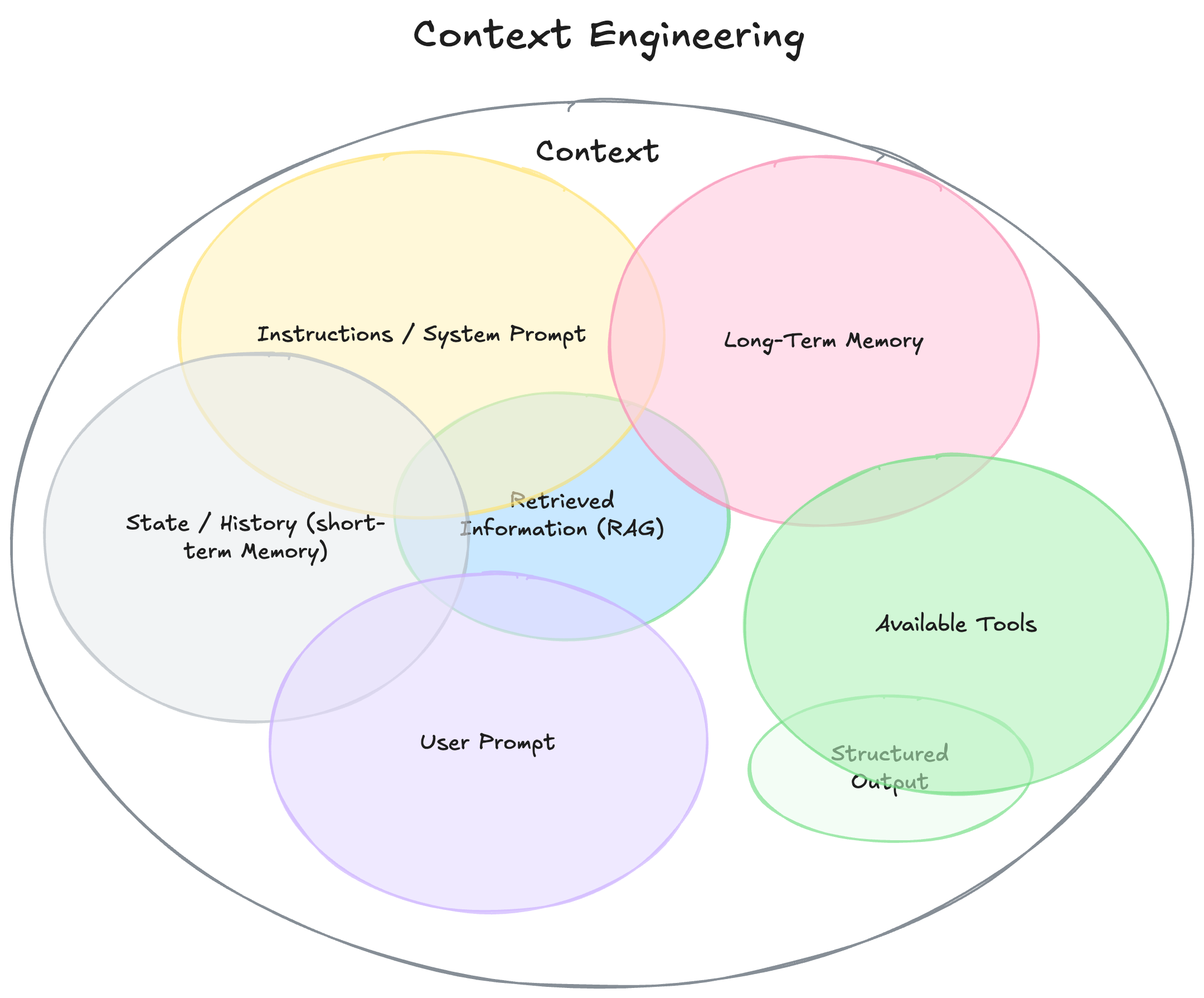
For those of us from data backgrounds, this isn’t new. Context Engineering is basically another take on “garbage in, garbage out.” In data projects we worry about sampling, data quality, and the business logic behind datasets. The same concerns apply to LLMs.
Why does context matter for LLM-powered applications? Because the benefits and costs of using an LLM depend heavily on the context you provide. Better input leads to more accurate outputs. No surprise.
Early LLMs managed only small context windows of a few thousand tokens. Newer models may handle up to a million words. You might think that means you can dump everything into the model. You can’t. More input increases response time and cost. It also bloats the model with irrelevant details and can reduce response quality.
Context Engineering in practice
To see how Context Engineering matters, let’s walk through two examples: a general chatbot and a coding agent.
For general Chatbots, take OpenAI’s Projects feature. Projects give ChatGPT shared context across chats and files, an easy way to create system prompts and attach files for RAG. Projects also extend the chat interface with specific prompts, tool access (like web exploration), and some kind of memory management. These UIs are useful, but one simple best practice works well: open and close chats instead of keeping a single chat open forever. That keeps context targeted, reduces wait times, and often improves response quality.
Tip
Keep context targeted and task-specific.
Different UIs require different habits. Coding assistants pass context in different ways. Some IDEs include every open tab as context. Asking an LLM to understand a massive codebase all at once is still ineffective. Good practices include asking for help about specific scripts (using @ or similar markers), limiting broad context, writing rules, and creating separate conversations for distinct tasks. And no, a MCP connection is usually not the answer, because it will likely flood the coding agent with unrelated information.
Context at the enterprise level
Scaling from individual chats to enterprise systems complicates things. Taming information efficiently is a major challenge for organizations. Too much information raises the bill for AI usage. Too little or the wrong kind of context can stall adoption if users don’t see productivity gains.
Enterprise systems add more friction. Finding relevant information across silos is hard, especially in large companies. Complex tasks often require stitching data from multiple sources to get a holistic view. Companies have invested heavily in data warehouses, data lakes, and lakehouses to make data accessible. But when data becomes widely available, few people truly understand how it was collected or the business logic behind it. That realization sparked talk of a semantic layer.
Now we need LLM agents to have the right context. Ideally, an LLM should select the correct sources using retrieval and toolchains. We’re at an early stage: we must populate the semantics layer and the data catalog because our “customers” are not only humans anymore, they are agents. We need to design a good Agent Experience (AX) (another new buzzword!) so agents can build their own context and reach their goals smoothly.
The information you feed your systems is core to output quality. Call it context, inputs, or data, name it what you like. Being mindful about Context Engineering will make you more effective in daily chats, coding, and building applications. To keep up with evolving systems, we’ll need good data preparation and stronger Data Governance. We’ll keep rebranding the same principles for years, but seriously, can we skip another Linkedin job title?