LightOnOCR-1B sets a new standard for how AI reads and understands business information and it does so at unprecedented speed. For decades, OCR has been about recognizing text; understanding it has always been out of reach. With LightOnOCR-1B, LightOn transforms document parsing from a slow, mechanical process into a fast, end-to-end semantic engine: machines don’t just “see” text, they comprehend it, in real time. This leap makes every contract, report, and archived document instantly usable by modern AI systems. (View Highlight)
At enterprise scale, speed is not a luxury, it’s a necessity. LightOnOCR-1B processes and structures massive document collections in record time, enabling organizations to index and unlock years of unstructured data effortlessly. Integrated into LightOn’s Private Enterprise Search, it turns organizational history into a living, searchable source of intelligence. In short: we make sense of your past, empowering GenAI to reason, summarize, and act upon your company’s entire knowledge base. (View Highlight)
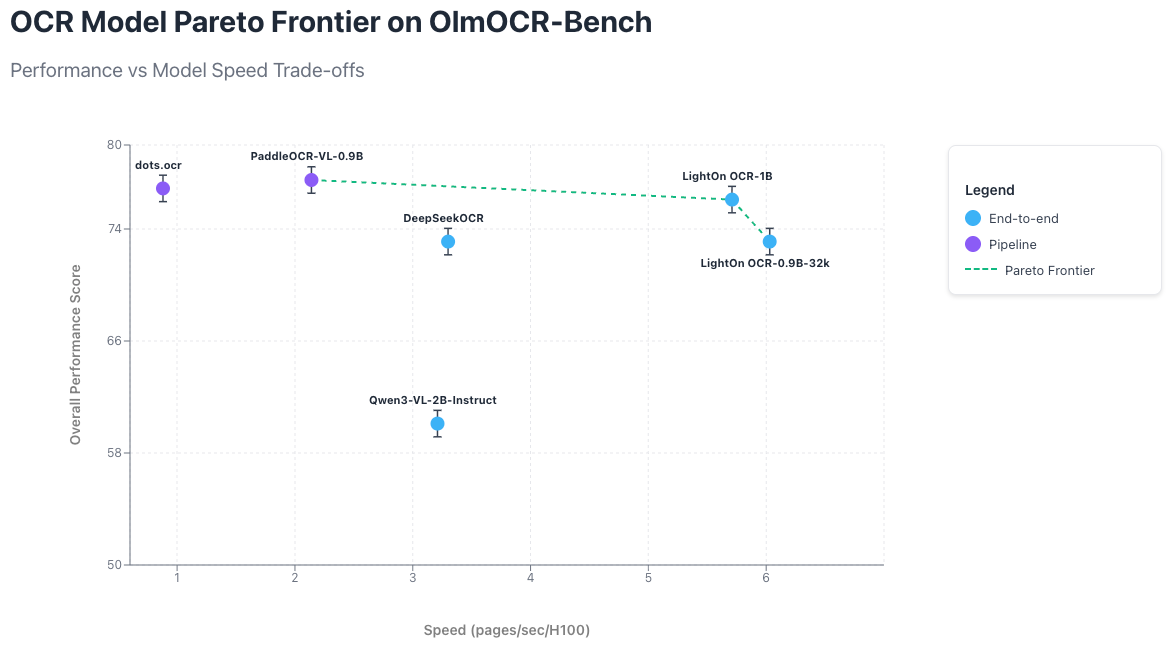
This blogpost introduces LightOnOCR-1B, a vision–language model for OCR that achieves state-of-the-art performance in its weight class while outperforming much larger general-purpose models. It achieves these results while running 6.49× faster than dots.ocr, 2.67× faster than PaddleOCR-VL-0.9B and 1.73× faster than DeepSeekOCR. Finally, unlike most recent approaches that rely on complex, non-trainable pipelines, LightOnOCR-1B is fully end-to-end trainable and easily fine-tunable for specific languages or domains. One of the key ingredients of LightOnOCR is its diverse large-scale PDF training corpus which will also be released with an open license soon. (View Highlight)
In this context, we release LightOnOCR, a compact, end-to-end model that delivers state-of-the-art document understanding with lightning speed and low cost. Competing systems(including newest releases) often rely on multiple moving parts to boost performance, but this added complexity makes them brittle, difficult to train, and prone to break when adapting to new data or domains. LightOnOCR, on the other hand, is a single unified model — fully differentiable and easy to optimize end-to-end — capable of handling complex layouts such as tables, forms, receipts, and scientific notation without fragile multi-stage pipelines. (View Highlight)
LightOnOCR is built by training a strong vision transformer with a lean language backbone and distilled from high-quality open VLMs. It is also highly efficient — processing 5.71 pages per second on a single H100 GPU, or roughly 493,000 pages per day. At current cloud pricing, that translates to less than $0.01 per 1,000 pages, making it several times cheaper than running larger OCR VLMs. We believe this will be of great interest to the community: the model is simple, stable, and inexpensive to fine-tune, making it easy to adapt to new domains, layouts, or languages. (View Highlight)
LightOnOCR is also available in two other variants with a pruned vocabulary of 32k tokens and 16k tokens, offering additional speedup for European languages while maintaining almost the same accuracy. (View Highlight)
We present our main results on Olmo-Bench the most common OCR benchmark, along with a comparison of inference speed against competing OCR systems.We choose not to include OmniDocBench for two different reasons: first the model is not optimized for Chinese and second, our model is optimized to output full page Markdown and not HTML. We discuss this a bit more in this section. (View Highlight)
LightOnOCR delivers performance on par with the latest state-of-the-art OCR systems. The model reaches state-of-the-art performance on Olmo-Bench for its size, including their most recent releases, and outperforms or closely matches much larger general-purpose VLMs without any training on OlmoOCR-mix. Indeed, unlike several reported baselines, LightOnOCR achieves these results without any benchmark-specific fine-tuning. Being a fully end-to-end model rather than a pipeline, it can be easily fine-tuned on specific domains such as OlmoOCR-mix to further improve performance, as shown in a later section. (View Highlight)
LightOnOCR notably beats DeepSeek OCR and performs on par with dots.ocr, despite the latter being roughly three times larger, and remains within the error margin of the pipeline-based PaddleOCR-VL and surpasses the larger Qwen3-VL-2B by 16 overall points. Beyond quality, its key advantage lies in efficiency: it matches the best available models while running significantly faster. (View Highlight)
The model is a 1B VLM obtained by combining a native resolution Vision Transformer (ViT) initialized from Pixtral and the Qwen3 language model architecture through a multimodality projection layer randomly initialized. In this layer, the vision tokens are first downsampled by a factor of 4 before being fed to the language model to reduce computational requirements. We also remove both the image break and image end tokens to simplify the architecture and use fewer image tokens overall per image. (View Highlight)
Although we start from pre-trained models, they are not aligned at first and so the training is of utmost importance. Our approach follows a knowledge distillation paradigm: we leverage a larger vision-language model to transcribe a large corpus of document pages, then train a smaller, specialized model on this synthetic dataset after careful curation.We employed Qwen2-VL-72B-Instruct as our base model, prompting it to transcribe content into Markdown with LaTeX notation. Markdown offers a lightweight, human-readable structure that is more token-efficient than HTML. It provides enough markup to preserve hierarchy and layout without unnecessary syntax, helping the model focus on content rather than formatting. Its simplicity also makes it easy to parse and convert into other formats, making it ideal for OCR output and downstream processing.Despite generally high-quality outputs, we observed several systematic issues requiring correction: generation loops, extraneous Markdown code block delimiters, superfluous formatting elements, and format inconsistencies (occasional HTML tables or LaTeX environments for arXiv-sourced documents). We therefore implemented a comprehensive normalization pipeline to ensure consistent, relevant transcriptions. (View Highlight)
We can see that the difference in performance between the two-stage setup and standard single-stage training is minimal with single-stage outperforming two-stage overall. We therefore moved away from the two-stage approach for simplicity. We believe this outcome is largely due to the scale of our dataset, which is significantly larger than those used in most comparable studies. This dataset will be released in a next step under an open license to support further research and development in open-source OCR and document understanding. (View Highlight)
This is similar to the findings in FineVision, where 2-stage training brings only marginal gains except for some tasks like OCRBench where the gains seemed to be important. Here, we confirm that multi-stage training does not provide any benefit even for OCR at 1B model size. (View Highlight)
We trained two models on an identical subset (11M samples) of our dataset, annotated either with Qwen2-VL-7B or Qwen2-VL-72B, to understand whether using a larger teacher model leads to better downstream performance. Both models share the same architecture and training setup; only the source of annotations differs. (View Highlight)
The results below show a clear advantage for data annotated by the larger teacher. (View Highlight)
These results indicate that while both teacher models produce usable annotations, the larger 72B model yields consistently stronger performance across all categories. The improvement is especially visible on complex structured layouts such as multi-column pages, long tiny text, tables, and mathematical content. (View Highlight)
This suggests that, for OCR, annotation quality scales with teacher size, and investing in a larger model for data generation can meaningfully improve downstream accuracy; even when the final trained model remains small. (View Highlight)
We use a native-resolution image encoder following the NaViT design, allowing the model to process documents at their original resolution. Since all our data are stored as PDFs, we control the rendering step and fix the DPI at 200 for simplicity. No resizing or complex preprocessing is applied; we only ensure that the rendered image’s maximum dimension does not exceed 1540 pixels for computational efficiency while maintaining aspect ratio. (View Highlight)
To understand the impact of image resolution at inference time, we ran an experiment varying the input size during inference. During training, images larger than 1024 pixels on their longest side are resized to 1024, while smaller images are kept at their native resolution. (View Highlight)
As shown in the table above, increasing the resolution at inference time consistently improves performance, especially on documents with dense text or small fonts. Higher-resolution inference proves particularly beneficial for Old Scans Math and Long Tiny Text, though it results in a slight drop in performance on table-heavy subsets. (View Highlight)
We tested light image-level augmentations similar to the Nougat paper to assess their impact on robustness. The goal was to simulate realistic document noise such as small rotations, scaling, grid distortions, and mild morphological operations like erosion and dilation, without affecting readability. (View Highlight)
The differences are small overall. Augmentations slightly improve robustness on noisy or irregular text (e.g. old_scans_math, long_tiny_text), but may reduce accuracy on clean structured subsets. Given the scale and diversity of our dataset, image augmentation does not bring measurable gains but we decide to use it in the final model as it could be a limitation of Olmo-bench having clean documents overall compared to real world. (View Highlight)
In this section, we want to highlight how easily LightOnOCR can be fine-tuned on domain-specific data, a key advantage over recent complex pipelines that cannot be adapted end-to-end. As an example, we use the OlmOCR-mix-0225 dataset and focus only on the documents subset, excluding books for which the source PDFs are not readily available in the dataset. (View Highlight)
To demonstrate adaptability, we start from the pre-trained LightOnOCR weights and fine-tune for a single epoch, with no additional hyperparameter tuning. (View Highlight)
Fine-tuning on the OlmOCR dataset leads to a clear performance gain, even without hyperparameter tuning. After just one epoch, the model reaches 77.2% overall and over 91% on headers and footers. This brings us already above many competitors such as MonkeyOCR-3B and around the level of MinerU2.5 on the benchmark, and could certainly be improved with further tuning. While not the main objective of our work, this simple fine-tune highlights how easily the model can adapt and confirms its versatility and suitability for further specialization tasks. (View Highlight)
This is an important distinction compared to pipeline-based approaches like dots.ocr, MinerU2.5, PaddleOCR, etc. Our model being end-to-end means we can continuously improve and adapt the model to specific data distributions by simply finetuning it, the same can not be said about pipelines where the different moving components would require a separate data annotation step. (View Highlight)
• Loop detection: We applied n-gram frequency analysis combined with prefix-based line clustering using Jaccard similarity metrics to identify and filter repetitive generation artifacts. We also discard samples that didn’t finish generation for a max output tokens of 6144, as these are likely repetitions or excessively long samples.
• Deduplication: We computed cryptographic hashes of sequences across our large-scale dataset to identify and remove duplicate samples.
• Image placeholder standardization: We normalized all image references to the format , enabling future users to substitute these with descriptive alt-text.
• Hallucination filtering: Since our dataset contained ground truth transcriptions from legacy OCR systems, we computed similarity scores between VLM outputs and reference OCR fields. This metric enabled the detection of hallucinations and generation failures, allowing us to filter samples with anomalously low similarity scores (e.g., outputs containing “I don’t see anything on this image” or other null responses).
This gives a dataset of 17.6 million pages and 45.5 billion tokens, combining both vision and text tokens rendered at native resolution, with a maximum image size of 1540 pixels.
This dataset will be permissively released soon. Also note that we use only this dataset in all of our ablations and final training (i.e, the final model is not trained using the Olmo-mix training set). (View Highlight)

 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight) (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)