We’ve found that synthesizing the results of multiple models can significantly outperform what individual models are capable of. Introducing Fusion: a tool for getting these combined results just as easily as calling a single model. It allows you to choose a panel of participant models alongside a judge model responsible for fusing the individual results together.
To understand the benefits of Fusion, we used a deep research benchmark that tests the combination of reasoning, tool usage, and knowledge. We found that:
Panels consistently outperform individual models
Beyond-frontier performance can be achieved with frontier panels
Panels of budget models can surpass frontier models and get close to frontier panel performance (View Highlight)
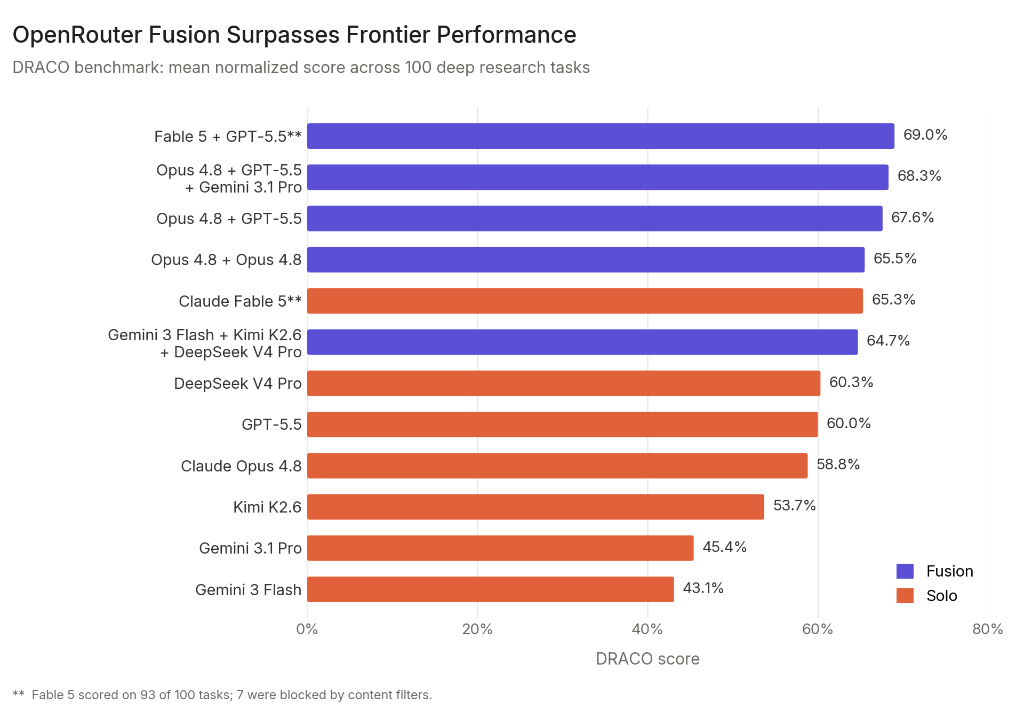
We tested Fusion on 100 deep research tasks from the DRACO benchmark. Some highlights of what we found:
• Fable 5 + GPT-5.5 fused together scored 69.0%, surpassing every individual model, including Fable 5 alone at 65.3%.
• A budget panel (Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro) beat GPT-5.5 and Opus 4.8. It came within 1% of Fable 5’s score while being 50% of the cost. (View Highlight)
One API call that fuses the best output of multiple models
When you send a prompt to Fusion, we dispatch it to a panel of models in parallel, each with web search and web fetch enabled. A judge model reads every panel response and produces structured analysis: consensus points, contradictions, partial coverage, unique insights, blind spots. The calling model then writes the final answer grounded in that analysis.
The whole pipeline runs server-side so it can be called just like you would an individual model. (View Highlight)
Preventing the Models from Cheating
When we gave the panel models web search, we discovered something alarming: they were finding the DRACO grading rubric online. While this was coincidental from search terms rather than intentional cheating, it still exposed a real contamination risk.
We solved this by excluding the locations where the results are hosted from web search and web fetch, preventing models from accessing pages related to the benchmark rubric. OpenRouter’s server tools support these exclude lists universally across all models by using a third party provider like Exa or Parallel, so applying them was a one-line config change rather than per-model patching. All results in this post were produced after the exclusion lists were in place.
If you are running your own evals, the same mechanism is available: pass excluded_domains to web_search or blocked_domains to web_fetch in your tool definitions to prevent the panel from accessing specific sources. (View Highlight)
Significant boost from fusing a model with itself
We ran Opus 4.8 partnered with itself as a two-model panel, with Opus 4.8 also serving as the synthesizer. The result: 65.5%, a 6.7-point jump over solo Opus 4.8 (58.8%). This suggests that a meaningful chunk of Fusion’s lift comes from the synthesis step itself, not just from combining different model architectures. Running the same prompt twice produces different reasoning paths, different tool calls, different source selections. It’s not enough to outperform a diverse set of models, but helps us understand the impact of the synthesis itself. (View Highlight)
Is Fusion a drop-in replacement for Fable?
No. The benchmark shows that fusing multiple models together can reach and surpass Fable-level performance on deep research tasks. We benchmarked one class of tasks (DRACO deep research), but the approach likely extends to many other workflows we haven’t tested yet. We’d love to hear about other use cases where you find it works well. (View Highlight)
How should I use Fusion for coding?
Fusion isn’t a drop-in replacement for coding models. Instead, it gives your coding model access to a server tool. The base model handles routine coding directly and can choose to call Fusion selectively on questions worth spending more time and money to get a thorough answer (e.g. architecture decisions or research on best practice approaches). The model decides when the question warrants multiple perspectives. (View Highlight)
DeepSeek V4 Pro’s performance was surprising. Is that accurate?
We were surprised by how well DeepSeek scored. At 60.3%, it performed similarly to both Opus 4.8 and GPT-5.5.
One hypothesis: Opus 4.8 would score higher with a larger tool-calling budget. It seems to be a hungrier model that performs better with more time and more tool use. Fable, by contrast, was better at using the tool-call budget judiciously and thinking for longer before acting. The benchmark’s fixed tool-call budget may have compressed the gap between models with different tool-use strategies. (View Highlight)
Is it slow? How much slower?
The model you make a request to performs the same as it would normally. The responses are only slower when your model encounters a problem that it thinks will benefit from using Fusion. When Fusion is invoked, it kicks off a multi-step process that is often 2-3x longer than a standard call. During this time it sends your prompt to multiple models, waits for them all to finish, then processes the results to produce the fused response. We did it this way to balance the speed of normal model execution with the availability of beyond-frontier answers to questions when you need it. (View Highlight)

 (View Highlight)
(View Highlight)