The course covers how to use langchain to chat with your data.
- Author: Andrew Ng, Harrison Chase
- Source: DLAI - Learning Platform Beta
This course is not focused on Langchain functioning, for that you can check the course titled LangChain for LLM Application Development
Document loading
In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution.
This is useful if we want to ask question about specific documents (e.g., our PDFs, a set of videos, etc).
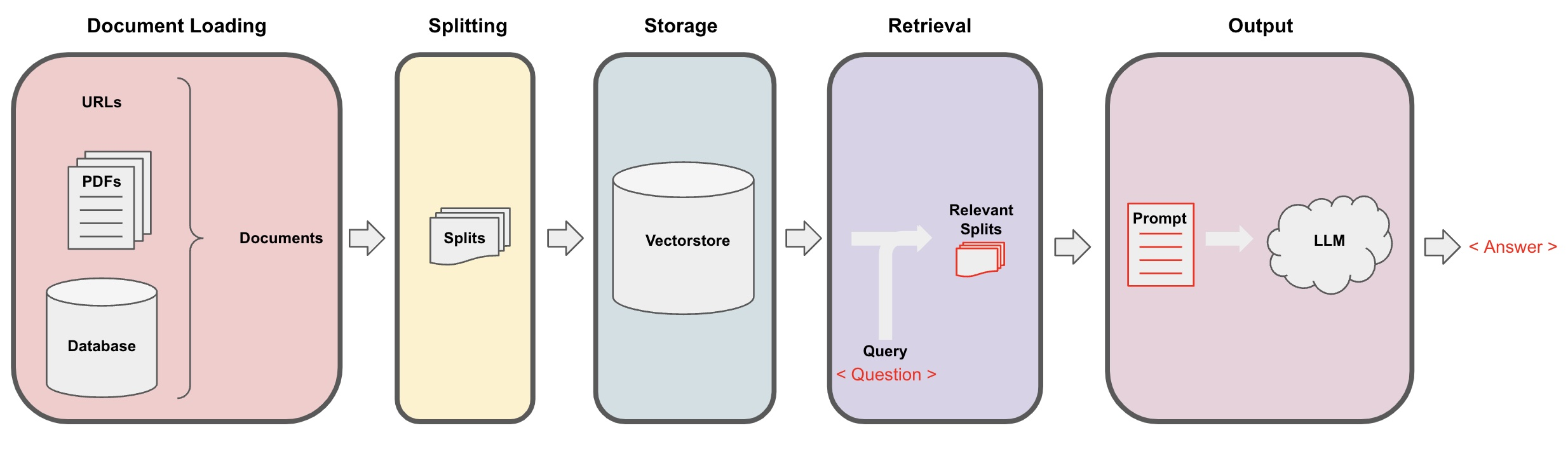
Document Splitting
Talks about how to split them up into smaller chunks. This may sound really easy, but there’s a lot of subtleties here that make a big impact down the line.
Document splitting happens after you load your data into the document format.
RecursiveCharacterTextSplitter is recommended for generic text.
c_splitter = CharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""]
)
we pass in a list of separators, and these are the default separators but we’re just putting them in this notebook to better show what’s going on. And so, we can see that we’ve got a list of double newline, single newline, space and then nothing, an empty string. "\n\n", "\n", " ", ""
What this mean is that when you’re splitting a piece of text it will first try to split it by double newlines. And then, if it still needs to split the individual chunks more it will go on to single newlines. And then, if it still needs to do more it goes on to the space. And then, finally it will just go character by character if it really needs to do that.

Looking at how these perform on the above text, we can see that the character text splitter splits on spaces. And so, we end up with the weird separation in the middle of the sentence.
The recursive text splitter first tries to split on double newlines, and so here it splits it up into two paragraphs. Even though the first one is shorter than the 450 characters, we specified this is probably a better split because now the two paragraphs that are each their own paragraphs are in the chunks as opposed to being split in the middle of a sentence.
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "\. ", " ", ""]
)
r_splitter.split_text(some_text)

Let’s now split it into even smaller chunks just to get an even better intuition as to what’s going on. We’ll also add in a period separator. This is aimed at splitting in between sentences. If we run this text splitter, we can see that it’s split on sentences, but the periods are actually in the wrong places. This is because of the regex that’s going on underneath the scenes. To fix this, we can actually specify a slightly more complicated regex with a look behind.
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
r_splitter.split_text(some_text)

Another way to split is with tokens. Tokens are the way LLMs view the text so it is a good alternative to replace text splitters.
A text splitting often uses sentences or other delimiters to keep related text together but many documents (such as Markdown) have structure (headers) that can be explicitly used in splitting. We can use MarkdownHeaderTextSplitter to preserve header metadata in our chunks, as show below.
Vectorstore and embeddings
Failure modes
This seems great, and basic similarity search will get you 80% of the way there very easily. But there are some failure modes that can creep up. Notice that we’re getting duplicate chunks (because of the duplicate MachineLearning-Lecture01.pdf in the index). Semantic search fetches all similar documents, but does not enforce diversity.
Retrieval
How to fix edge cases.
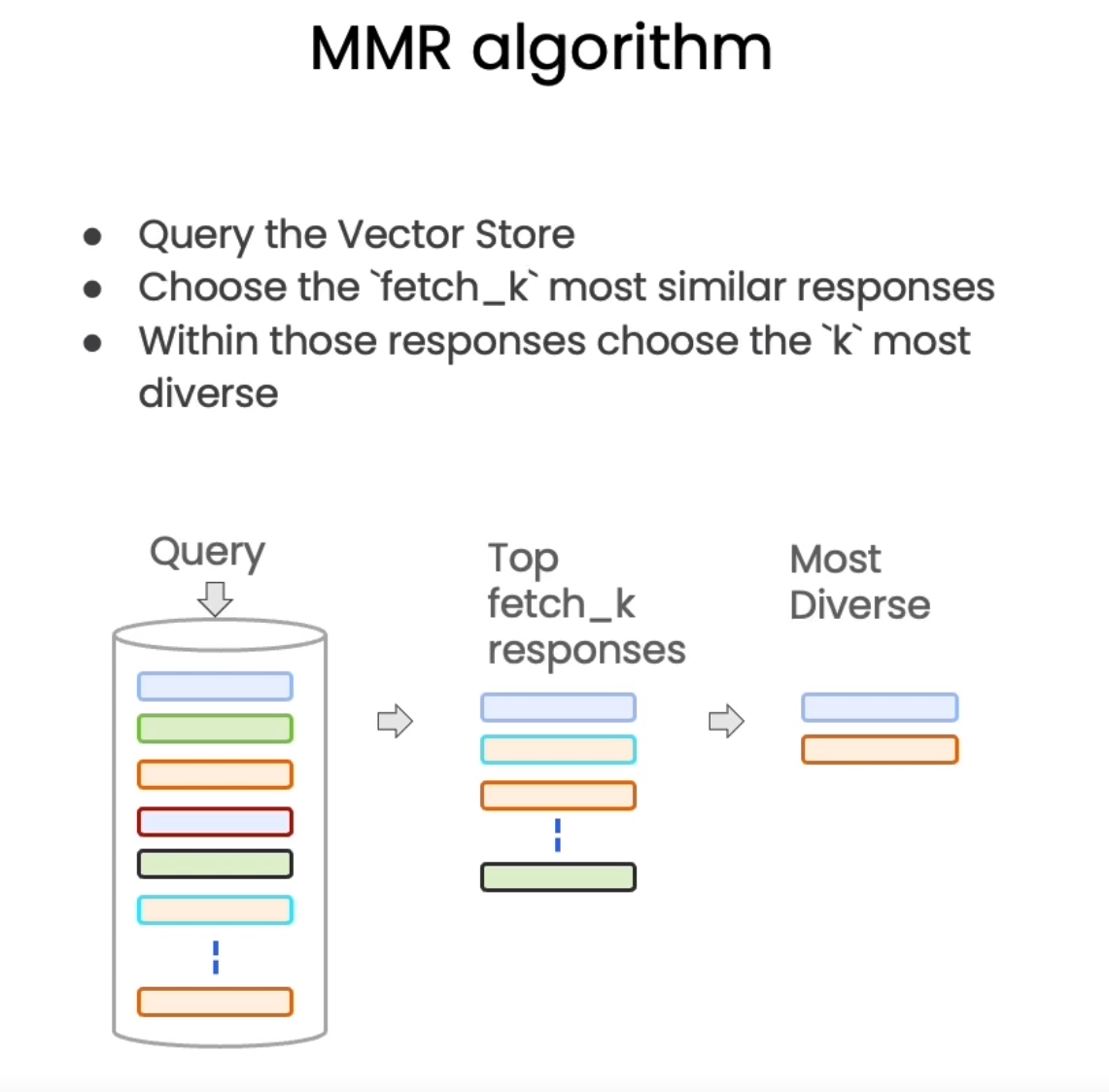
Maximum marginal relevance
Maximum marginal relevance, you may not always want to choose the most similar results. Maximum marginal relevance strives to achieve both relevance to the query and diversity among the results.
SelfQuery
SelfQuery, semantic part and also explode the information on the metadata (a search and a filter term). We often want to infer the metadata from the query itself.
To address this, we can use SelfQueryRetriever, which uses an LLM to extract:
- The
querystring to use for vector search - A metadata filter to pass in as well Most vector databases support metadata filters, so this doesn’t require any new databases or indexes.
The self query retriever in particular is Harrison’s favorite. So he would suggest trying that out with more and more complex metadata filters. Even maybe making up some metadata where there’s really nested metadata structures and you can try to get the LLM to infer that.
Compression
Compression, extracts the most relevant segments. Information most relevant to a query may be buried in a document with a lot of irrelevant text.
Passing that full document through your application can lead to more expensive LLM calls and poorer responses.
Combining various techniques
You can combine compression and MMR or others
Question answering
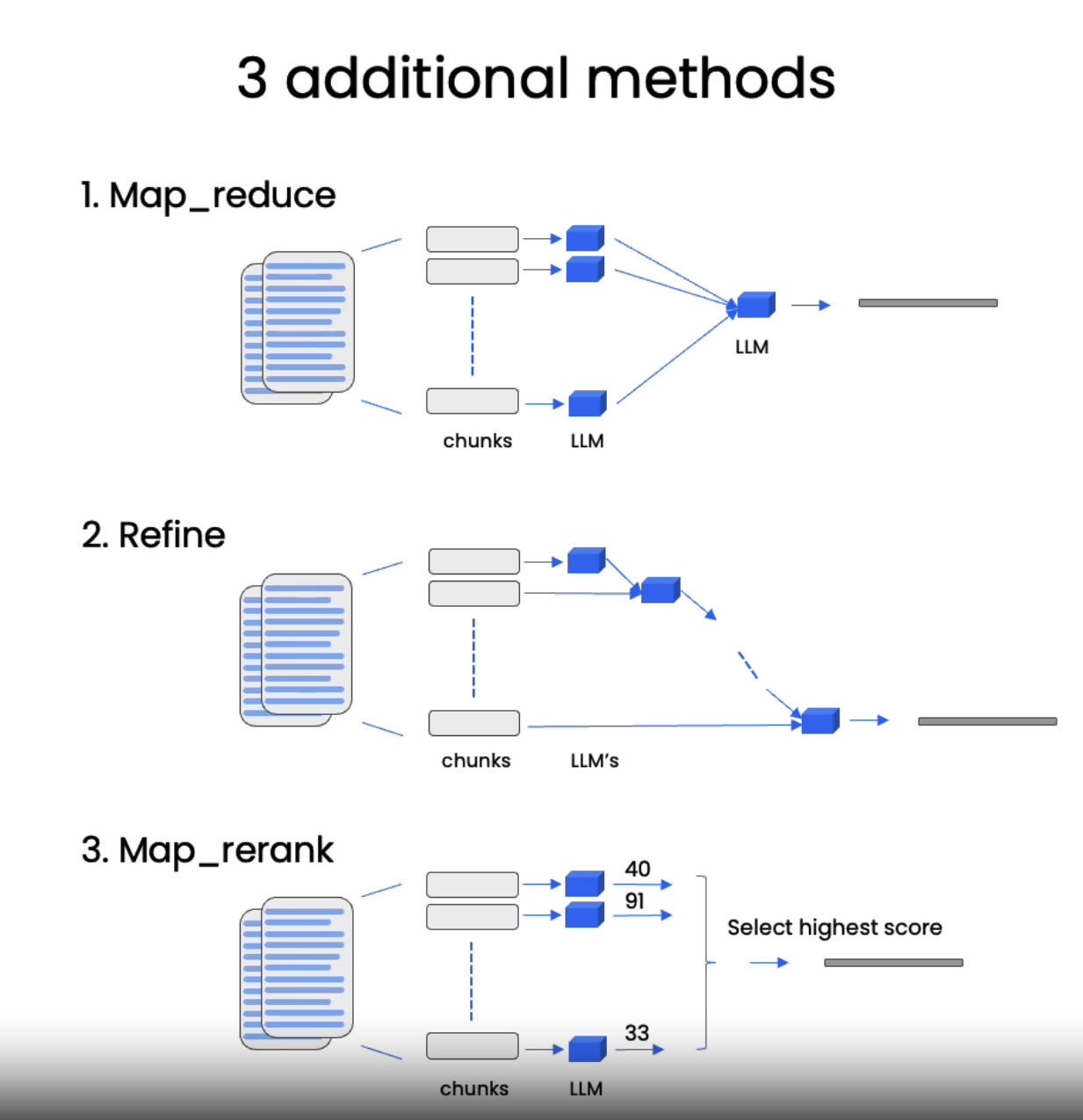
You can concatenated the retrieved documents with stuff or if the retrieved documents does not fit with the context you can use any of the following methods:
Chat
Allows user to ask follow up questions and the chat will be able to add that information to context. You can add memory including chat history as a list of messages.
Transcript
Hi, I’m excited to share with you this new course on using LangChain to chat with your data. This is built in collaboration with Harrison Chase, co-founder and CEO of LangChain. Large language models or LLMs such as ChatGPT can answer questions about a lot of topics, but an LLM in isolation knows only what it was trained on, which doesn’t include your personal data, such as if you’re in a company and have proprietary documents not on the internet, as well as data or articles that were written after the LLM was trained. So wouldn’t it be useful if you or others such as your customers can have a conversation with your own documents and get questions answered using information from those documents and using an LLM? In this short course, we will cover how to use LangChain to chat with your data. LangChain is an open-source developer framework for building LLM applications. LangChain consists of several modular components as well as more end-to-end templates. The modular components in LangChain include prompts, models, indexes, chains, and agents. For a more detailed look at these components, you can see our first course that I taught with Andrew. In this course, we will zoom in and focus on one of the more popular use cases of LangChain, how to use LangChain to chat with your data. We will first cover how to use LangChain document loaders to load data from a variety of exciting sources. We will then touch on how to split these documents into semantically meaningful chunks. This pre-processing step may seem simple but has a lot of nuance. Next, we’ll give an overview of semantic search, a basic method for fetching relevant information given a user question. This is the easiest method to get started with but there are several cases where it fails. We’ll go over these cases and then we’ll go over how to fix them. We’ll then show how to use those retrieved documents to enable an LLM to answer questions about a document but show that you’re still missing one key piece in order to fully recreate that chatbot experience. Finally, we’ll cover that missing piece, memory, and show how to build a fully functioning chatbot through which you can chat with your data. This will be an exciting short course. We’re grateful to Ankush Gola as well as Lance Martin from the LangChain team for working on all the materials that you hear Harrison present later, as well as on the deeplearning.ai side, Geoff Ladwig and Diala Ezzeddine. In case you’re going through this course and decide you’d like a refresher on the basics of LangChain, I encourage you to also take that earlier short course on LangChain for LLM application development that Harrison had mentioned as well. But with that, let us now go on to the next video where Harrison will show you how to use LangChain’s very convenient collection of document loaders.
In order to create an application where you can chat with your data, you first have to load your data into a format where it can be worked with. That’s where LangChain document loaders come into play. We have over 80 different types of document loaders, and in this lesson we’ll cover a few of the most important ones and get you comfortable with the concept in general. Let’s jump in! Document loaders deal with the specifics of accessing and converting data from a variety of different formats and sources into a standardized format. There can be different places that we want to load data from, like websites, different databases, YouTube, and these documents can come in different data types, like PDFs, HTML, JSON. And so the whole purpose of document loaders is to take this variety of data sources and load them into a standard document object. Which consists of content and then associated metadata. There are a lot of different type of document loaders in LangChain, and we won’t have time to cover them all, but here is a rough categorization of the 80 plus that we have. There are a lot that deal with loading unstructured data, like text files, from public data sources, like YouTube, Twitter, Hacker News, and there are also even more that deal with loading unstructured data from the proprietary data sources that you or your company might have, like Figma, Notion. Document loaders can also be used to load structured data. Data that’s in a tabular format and may just have some text data in one of those cells or rows that you still want to do question answering or semantic search over. And so the sources here include things like Airbyte, Stripe, Airtable. Alright, now let’s jump into the fun stuff, actually using document loaders. First, we’re going to load some environment variables that we need, like the OpenAI API key. The first type of documents that we’re going to be working with are PDFs. So let’s import the relevant document loader from Langchain. We’re going to use the PyPDF loader. We’ve loaded a bunch of PDFs into the documents folder in the workspace, and so let’s choose one and put that in the loader. Now let’s load the documents by just calling the load method. Let’s take a look at what exactly we’ve loaded. So this, by default, will load a list of documents. In this case, there are 22 different pages in this PDF. Each one is its own unique document. Let’s take a look at the first one and see what it consists of. The first thing the document consists of is some page content, which is the content of the page. This can be a bit long, so let’s just print out the first few hundred characters. The other piece of information that’s really important is the metadata associated with each document. This can be accessed with the metadata element. You can see here that there’s two different pieces. One is the source information. This is the PDF, the name of the file that we loaded it from. The other is the page field. This corresponds to the page of the PDF that it was loaded from. The next type of document loader that we’re going to look at is one that loads from YouTube. There’s a lot of fun content on YouTube, and so a lot of people use this document loader to be able to ask questions of their favorite videos or lectures or anything like that. We’re going to import a few different things here. The key parts are the YouTube audio loader, which loads an audio file from a YouTube video. The other key part is the OpenAI Whisper parser. This will use OpenAI’s Whisper model, a speech-to-text model, to convert the YouTube audio into a text format that we can work with. We can now specify a URL, specify a directory in which to save the audio files, and then create the generic loader as a combination of this YouTube audio loader combined with the OpenAI Whisper parser. And then we can call “loader.load” to load the documents corresponding to this YouTube. This may take a few minutes, so we’re going to speed this up and post. Now that it’s finished loading, we can take a look at the page content of what we’ve loaded. And this is the first part of the transcript from the YouTube video. This is a good time to pause, go choose your favorite YouTube video, and see if this transcription works for you. The next set of documents that we’re going to go over how to load are URLs from the Internet. There’s a lot of really awesome educational content on the Internet, and wouldn’t it be cool if you could just chat with it? We’re going to enable that by importing the web-based loader from LangChain. Then we can choose any URL, our favorite URL. Here, we’re going to choose a markdown file from this GitHub page and create a loader for it. And then next, we can call loader.load, and then we can take a look at the content of the page. Here, you’ll notice there’s a lot of white space, followed by some initial text, and then some more text. This is a good example of why you actually need to do some post-processing on the information to get it into a workable format. Finally, we’ll cover how to load data from Notion. Notion is a really popular store of both personal and company data, and a lot of people have created chatbots talking to their Notion databases. In your notebook, you’ll see instructions on how to export data from your Notion database into a format through which we can load it into LangChain. Once we have it in that format, we can use the Notion directory loader to load that data and get documents that we can work with. If we take a look at the content here, we can see that it’s in markdown format, and this Notion document is from Blendle’s Employee Handbook. I’m sure a lot of people listening have used Notion and have some Notion databases that they would like to chat with, and so this is a great opportunity to go export that data, bring it in here, and start working with it in this format. That’s it for document loading. Here, we’ve covered how to load data from a variety of sources and get it into a standardized document interface. However, these documents are still rather large, and so in the next section, we’re going to go over how to split them up into smaller chunks. This is relevant and important because when you’re doing this retrieval augmented generation, you need to retrieve only the pieces of content that are most relevant, and so you don’t want to select the whole documents that we’ve loaded here, but rather only the paragraph or few sentences that are most topical to what you’re talking about. This is also an even better opportunity to think about what sources of data we don’t currently have loaders for, but you might still want to explore. Who knows? Maybe you can even make a PR to LangChain.
We just went over how to load documents into a standard format. Now, we’re going to talk about how to split them up into smaller chunks. This may sound really easy, but there’s a lot of subtleties here that make a big impact down the line. Let’s jump into it! Document splitting happens after you load your data into the document format. But before, it goes into the vector store, and this may seem really simple. You can just split the chunks according to the lengths of each character or something like that. But as an example of why this is both trickier and very important down the line, let’s take a look at this example here. We’ve got a sentence about the Toyota Camry and some specifications. And if we did a simple splitting, we could end up with part of the sentence in one chunk, and the other part of the sentence in another chunk. And then, when we’re trying to answer a question down the line about what are the specifications on the Camry, we actually don’t have the right information in either chunk, and so it’s split apart. And so, we wouldn’t be able to answer this question correctly. So, there’s a lot of nuance and importance in how you split the chunks so that you get semantically relevant chunks together. The basis of all the text splitters in Lang Chain involves splitting on chunks in some chunk size with some chunk overlap. And so, we have a little diagram here below to show what that looks like. So, the chunk size corresponds to the size of a chunk, and the size of the chunk can be measured in a few different ways. And we’ll talk about a few of those in the lesson. And so, we allow passing in a length function to measure the size of the chunk. This is often characters or tokens. A chunk overlap is generally kept as a little overlap between two chunks, like a sliding window as we move from one to the other. And this allows for the same piece of context to be at the end of one chunk and at the start of the other and helps create some notion of consistency. The text splitters in Lang Chain all have a create documents and a split documents method. This involves the same logic under the hood, it just exposes a slightly different interface, one that takes in a list of text and another that takes in a list of documents. There are a lot of different types of splitters in Lang Chain, and we’ll cover a few of them in this lesson. But, I would encourage you to check out the rest of them in your spare time. These text splitters vary across a bunch of dimensions. They can vary on how they split the chunks, what characters go into that. They can vary on how they measure the length of the chunks. Is it by characters? Is it by tokens? There are even some that use other smaller models to determine when the end of a sentence might be and use that as a way of splitting chunks. Another important part of splitting into chunks is also the metadata. Maintaining the same metadata across all chunks, but also adding in new pieces of metadata when relevant, and so there are some text splitters that are really focused on that. The splitting of chunks can often be specific on the type of document that we’re working with, and this is really apparent when you’re splitting on code. So, we have a language text splitter that has a bunch of different separators for a variety of different languages like Python, Ruby, C. And when splitting these documents, it takes those different languages and the relevant separators for those languages into account when it’s doing the splitting. First, we’re going to set up the environment as before by loading the Open AIAPI key. Next, we’re going to import two of the most common types of text splitters in Lang Chain. The recursive character text splitter and the character text splitter. We’re going to first play around with a few toy use cases just to get a sense of what exactly these do. And so, we’re going to set a relatively small chunk size of 26, and an even smaller chunk overlap of 4, just so we can see what these can do. Let’s initialize these two different text splitters as R splitter and C splitter. And then let’s take a look at a few different use cases. Let’s load in the first string. A, B, C, D, all the way down to Z. And let’s look at what happens when we use the various splitters. When we split it with the recursive character text splitter it still ends up as one string. This is because this is 26 characters long and we’ve specified a chunk size of 26. So, there’s actually no need to even do any splitting here. Now, let’s do it on a slightly longer string where it’s longer than the 26 characters that we’ve specified as the chunk size. Here we can see that two different chunks are created. The first one ends at Z, so that’s 26 characters. The next one we can see starts with W, X, Y, Z. Those are the four chunk overlaps, And then it continues with the rest of the string. Let’s take a look at a slightly more complex string where we have a bunch of spaces between characters. We can now see that it’s split into three chunks because there are spaces, so it takes up more space. And so, if we look at the overlap we can see that in the first one there’s L and M, and L and M are then also present in the second one. That seems like only two characters but because of the space both in between the L and M, and then also, before the L and after the M that actually counts as the four that makes up the chunk overlap. Let’s now try with the character text splitter, And we can see that when we run it doesn’t actually try to split it at all. And so, what’s going on here? The issue is the character text splitter splits on a single character and by default that character is a newline character. But here, there are no newlines. If we set the separator to be an empty space, we can see what happens then. Here it’s split in the same way as before. This is a good point to pause the video, and try some new examples both with different strings that you’ve made up. And then, also swapping out the separators and seeing what happens. It’s also interesting to experiment with the chunk size, and chunk overlap, and just generally get a sense for what’s happening in a few toy examples so that when we move on to more real-world examples, you’ll have good intuition as to what’s happening underneath the scenes. Now, let’s try it out on some more real-world examples. We’ve got this long paragraph here, and we can see that right about here, we have this double newline symbol which is a typical separator between paragraphs. Let’s check out the length of this piece of text, and we can see that it’s just about 500. And now, let’s define our two text splitters. We’ll work with the character text splitter as before with the space as a separator and then we’ll initialize the recursive character text splitter. And here, we pass in a list of separators, and these are the default separators but we’re just putting them in this notebook to better show what’s going on. And so, we can see that we’ve got a list of double newline, single newline, space and then nothing, an empty string. What this mean is that when you’re splitting a piece of text it will first try to split it by double newlines. And then, if it still needs to split the individual chunks more it will go on to single newlines. And then, if it still needs to do more it goes on to the space. And then, finally it will just go character by character if it really needs to do that. Looking at how these perform on the above text, we can see that the character text splitter splits on spaces. And so, we end up with the weird separation in the middle of the sentence. The recursive text splitter first tries to split on double newlines, and so here it splits it up into two paragraphs. Even though the first one is shorter than the 450 characters, we specified this is probably a better split because now the two paragraphs that are each their own paragraphs are in the chunks as opposed to being split in the middle of a sentence. Let’s now split it into even smaller chunks just to get an even better intuition as to what’s going on. We’ll also add in a period separator. This is aimed at splitting in between sentences. If we run this text splitter, we can see that it’s split on sentences, but the periods are actually in the wrong places. This is because of the regex that’s going on underneath the scenes. To fix this, we can actually specify a slightly more complicated regex with a look behind. Now, if we run this, we can see that it’s split into sentences, and it’s split properly with the periods being in the right places. Let’s now do this on an even more real-world example with one of the PDFs that we worked with in the first document loading section. Let’s load it in, and then let’s define our text splitter here. Here we pass the length function. This is using LEN, the Python built-in. This is the default, but we’re just specifying it for more clarity what’s going on underneath the scenes, and this is counting the length of the characters. Because we now want to use documents, we’re using the split documents method, and we’re passing in a list of documents. If we compare the length of those documents to the length of the original pages, we can see that there’s been a bunch more documents that have been created as a result of this splitting. We can do a similar thing with the Notion DB that we used in the first lecture as well. And once again, comparing the lengths of the original documents to the new split documents, we can see that we’ve got a lot more documents now that we’ve done all the splitting. This is a good point to pause the video, and try some new examples. So far, we’ve done all the splitting based on characters. But, there’s another way to split, and this is based on tokens, and for this let’s import the token text splitter. The reason that this is useful is because often LLMs have context windows that are designated by token count. And so, it’s important to know what the tokens are, and where they appear. And then, we can split on them to have a slightly more representative idea of how the LLM would view them. To really get a sense for what the difference is between tokens and characters. Let’s initialize the token text splitter with a chunk size of 1, and a chunk overlap of 0. So, this will split any text into a list of the relevant tokens. Let’s create a fun made-up text, and when we split it, we can see that it’s split into a bunch of different tokens, and they’re all a little bit different in terms of their length and the number of characters in them. So, the first one is just foo then you’ve got a space, and then bar, and then you’ve got a space, and just the B then AZ then ZY, and then foo again. And this shows a little bit of the difference between splitting on characters versus splitting on tokens. Let’s apply this to the documents that we loaded above, and in a similar way, we can call the split documents on the pages, and if we take a look at the first document, we have our new split document with the page content being roughly the title, and then we’ve got the metadata of the source and the page where it came from. You can see here that the metadata of the source and the page is the same in the chunk as it was for the original document and so if we take a look at that just to make sure pages 0 metadata, we can see that it lines up. This is good it’s carrying through the metadata to each chunk appropriately, but there can also be cases where you actually want to add more metadata to the chunks as you split them. This can contain information like where in the document, the chunk came from where it is relative to other things or concepts in the document and generally this information can be used when answering questions to provide more context about what this chunk is exactly. To see a concrete example of this, let’s look at another type of text splitter that actually adds information into the metadata of each chunk. You can now pause and try a few examples that you come up with. This text splitter is the markdown header text splitter and what it will do is it will split a markdown file based on the header or any subheaders and then it will add those headers as content to the metadata fields and that will get passed on along to any chunks that originate from those splits. Let’s do a toy example first, and play around with a document where we’ve got a title and then a subheader of chapter 1. We’ve then got some sentences there, and then another section of an even smaller subheader, and then we jump back out to chapter 2, and some sentences there. Let’s define a list of the headers we want to split on and the names of those headers. So first, we’ve got a single hashtag and we’ll call that header 1. We’ve then got two hashtags, header 2, three hashtags, header 3. We can then initialize the markdown header text splitter with those headers, and then split the toy example we have above. If we take a look at a few of these examples, we can see the first one has the content, “Hi, this is Jim .” “Hi, this is Joe.” And now in the metadata, we have header 1, and then we have it as title and header 2 as chapter 1, and this is coming from right here in the example document above. Let’s take a look at the next one, and we can see here that we’ve jumped down into an even smaller subsection. And so, we’ve got the content of “Hi, this is Lance” and now we’ve got not only header 1. But also header 2, and also header 3, and this is again coming from the content and names in the markdown document above. Let’s try this out on a real-world example. Before, we loaded the notion directory using the notion directory loader and this loaded the files to markdown which is relevant for the markdown header splitter. So, let’s load those documents, and then define the markdown splitter with header 1 as a single hashtag and header 2 as a double hashtag. We split the text and we get our splits. If we take a look at them, we can see that the first one has content of some page, and now if we scroll down to the metadata, we can see that we’ve loaded header 1 as Blendel’s employee handbook. We’ve now gone over how to get semantically relevant chunks with appropriate metadata. The next step is moving those chunks of data into a vector store, and we’ll cover that in the next section.
We’ve now got our document split up into small, semantically meaningful chunks, and it’s time to put these chunks into an index, whereby we can easily retrieve them when it comes time to answer questions about this corpus of data. To do that, we’re going to utilize embeddings and vector stores. Let’s see what those are. We covered this briefly in the previous course, but we’re going to revisit it for a few reasons. First, these are incredibly important for building chatbots over your data. And second, we’re going to go a bit deeper, and we’re going to talk about edge cases, and where this generic method can actually fail. Don’t worry, we’re going to fix those later on. But for now, let’s talk about vector stores and embeddings. And this comes after text splitting, when we’re ready to store the documents in an easily accessible format. What embeddings are? They take a piece of text, and they create a numerical representation of that text. Text with similar content will have similar vectors in this numeric space. What that means is we can then compare those vectors and find pieces of text that are similar. So, in the example below, we can see that the two sentences about pets are very similar, while a sentence about a pet and a sentence about a car are not very similar. As a reminder of the full end-to-end workflow, we start with documents, we then create smaller splits of those documents, we then create embeddings of those documents, and then we store all of those in a vector store. A vector store is a database where you can easily look up similar vectors later on. This will become useful when we’re trying to find documents that are relevant for a question at hand. We can then take the question at hand, create an embedding, and then do comparisons to all the different vectors in the vector store, and then pick the n most similar. We then take those n most similar chunks, and pass them along with the question into an LLM, and get back an answer. We’ll cover all of that later on. For now, it’s time to deep dive on embeddings and vector stores themselves. To start, we’ll once again set the appropriate environment variables. From here on out, we’re going to be working with the same set of documents. These are the CS229 lectures. We’re going to load a few of them here. Notice that we’re actually going to duplicate the first lecture. This is for the purposes of simulating some dirty data. After the documents are loaded, we can then use the recursive character text splitter to create chunks. We can see that we’ve now created over 200 different chunks. Time to move on to the next section and create embeddings for all of them. We’ll use OpenAI to create these embeddings. Before jumping into a real-world example, let’s try it out with a few toy test cases just to get a sense for what’s going on underneath the hood. We’ve got a few example sentences where the first two are very similar and the third one is unrelated. We can then use the embedding class to create an embedding for each sentence. We can then use NumPy to compare them, and see which ones are most similar. We expect that the first two sentences should be very similar, and then the first and second compared to the third shouldn’t be nearly as similar. We’ll use a dot product to compare the two embeddings. If you don’t know what a dot product is, that’s fine. The important thing to know is that higher is better. Here we can see that the first two embeddings have a pretty high score of 0.96. If we compare the first embedding to the third one, we can see that it’s significantly lower at 0.77. And if we compare the second to the third, we can see it’s right about the same at 0.76. Now is a good time to pause, and try out a few sentences of your own, and see what the dot product is. Let’s now get back to the real-world example. It’s time to create embeddings for all the chunks of the PDFs and then store them in a vector store. The vector store that we’ll use for this lesson is Chroma. So, let’s import that. LangChain has integrations with lots, over 30 different vector stores. We choose Chroma because it’s lightweight and in memory, which makes it very easy to get up and started with. There are other vector stores that offer hosted solutions, which can be useful when you’re trying to persist large amounts of data or persist it in cloud storage somewhere. We’re going to want to save this vector store so that we can use it in future lessons. So, let’s create a variable called persist directory, which we will use later on at docs slash Chroma. Let’s also just make sure that nothing is there already. If there’s stuff there already, it can throw things off and we don’t want that to happen. So, let’s RM dash RF docs dot Chroma just to make sure that there’s nothing there. Let’s now create the vector store. So, we call Chroma from documents, passing in splits, and these are the splits that we created earlier, passing in embedding. And this is the open AI embedding model and then passing in persist directory, which is a Chroma specific keyword argument that allows us to save the directory to disk. If we take a look at the collection count after doing this, we can see that it’s 209, which is the same as the number of splits that we had from before. Let’s now start using it. Let’s think of a question that we can ask of this data. We know that this is about a class lecture. So, let’s ask if there is any email that we can ask for help if we need any help with the course or material or anything like that. We’re going to use the similarity search method, and we’re going to pass in the question, and then we’ll also pass in K equals three. This specifies the number of documents that we want to return. So, if we run that and we look at the length of the documents, we can see that it’s three as we specified. If we take a look at the content of the first document, we can see that it is in fact about an email address, cs229-qa.cs.stanford.edu. And this is the email that we can send questions to and is read by all the TAs. After doing so, let’s make sure to persist the vector database so that we can use it in future lessons by running vectordb.persist. This has covered the basics of semantic search and shown us that we can get pretty good results based on just embeddings alone. But it isn’t perfect and here we’ll go over a few edge cases and show where this can fail. Let’s try a new question. What did they say about MATLAB? Let’s run this specifying K equals five and get back some results. If we take a look at the first two results, we can see that they’re actually identical. This is because when we loaded in the PDFs, if you remember, we specified on purpose a duplicate entry. This is bad because we’ve got the same information in two different chunks and we’re going to be passing both of these chunks to the language model down the line. There’s no real value in the second piece of information and it would be much better if there was a different distinct chunk that the language model could learn from. One of the things that we’ll cover in the next lesson is how to retrieve both relevant and distinct chunks at the same time. There’s another type of failure mode that can also happen. Let’s take a look at the question, what did they say about regression in the third lecture? When we get the docs for this, intuitively we would expect them to all be part of the third lecture. We can check this because we have information in the metadata about what lectures they came from. So, let’s loop over all the documents and print out the metadata. We can see that there’s actually a combination of results, some from the third lecture, some from the second lecture, and some from the first. The intuition about why this is failing is that the third lecture and the fact that we want documents from only the third lecture is a piece of structured information, but we’re just doing a semantic lookup based on embeddings where it creates an embedding for the whole sentence and it’s probably a bit more focused on regression. Therefore, we’re getting results that are probably pretty relevant to regression and so if we take a look at the fifth doc, the one that comes from the first lecture, we can see that it does in fact mention regression. So, it’s picking up on that, but it’s not picking up on the fact that it’s only supposed to be querying documents from the third lecture because again, that’s a piece of structured information that isn’t really perfectly captured in this semantic embedding that we’ve created. Now’s a good time to pause and try out a few more queries. What other edge cases can you notice that arise? You can also play around with changing k, the number of documents that you retrieve. As you may have noticed throughout this lesson, we used first three and then five. You can try adjusting it to be whatever you want. You’ll probably notice that when you make it larger, you’ll retrieve more documents, but the documents towards the tail end of that may not be as relevant as the ones at the beginning. Now, that we’ve covered the basics of semantic search and also some of the failure modes, let’s go on to the next lesson. We’ll talk about how to address those failure modes and beef up our retrieval.
In the last lesson, we covered the basics of semantic search and saw that it worked pretty well for a good amount of use cases. But we also saw some edge cases and saw how things could go a little bit wrong. In this lesson, we’re going to deep dive on retrieval and cover a few more advanced methods for overcoming those edge cases. I’m really excited by this because I think retrieval is something that is new and a lot of the techniques we’re talking about have popped up in the past few months or so. And this is a cutting edge topic and so you guys are going to be right at the forefront. Let’s have some fun. In this lesson, we’re going to talk about retrieval. This is important at query time, when you’ve got a query that comes in and you want to retrieved the most relevant splits. We talked in the previous lesson about semantic similarity search, but we’re going to talk about a few different and more advanced methods here. The first one we’re going to cover is Maximum Marginal Relevance, or MMR. And so the idea behind this is that if you just always take the documents that are most similar to the query in the embedding space, you may actually miss out on diverse information, as we saw in one of the edge cases. In this example, we’ve got a chef asking about all white mushrooms. And so if we take a look at the most similar results, those would be the first two documents, where they have a lot of information similar to the query about a fruiting body and being all white. But we really want to make sure that we also get other information, like the fact that it’s really poisonous. And so this is where using MMR comes into play, as it will select for a diverse set of documents. The idea behind MMR is that we send a query in, and then we initially get back a set of responses, with “fetch_k” being a parameter that we can control in order to determine how many responses we get. This is based solely on semantic similarity. From there, we then work with that smaller set of documents and optimize for not only the most relevant ones, based on semantic similarity, but also ones that are diverse. And from that set of documents, we choose a final “k” to return to the user. Another type of retrieval we can do is what we call self-query. So this is useful when you get questions that aren’t solely about the content that you want to look up semantically, but also include some mention of some metadata that you want to do a filter on. So let’s take the question, what are some movies about aliens made in 1980? This really has two components to it. It’s got a semantic part, the aliens bit. So we want to look up aliens in our database of movies. But it’s also got a piece that really refers to the metadata about each movie, which is the fact that the year should be 1980. What we can do is we can use a language model itself to split that original question into two separate things, a filter and a search term. Most vector stores support a metadata filter. So you can easily filter records based on metadata, like the year being 1980. Finally, we’ll talk about compression. This can be useful to really pull out only the most relevant bits of the retrieved passages. For example, when asking a question, you get back the whole document that was stored, even if only the first one or two sentences are the relevant parts. With compression, you can then run all those documents through a language model and extract the most relevant segments and then pass only the most relevant segments into a final language model call. This comes at the cost of making more calls to the language model, but it’s also really good for focusing the final answer on only the most important things. And so it’s a bit of a tradeoff. Let’s see these different techniques in action. We’re going to start by loading the environment variables as we always do. Let’s then import Chroma and OpenAI as we used them before. And we can see by looking at the collection count that it’s got the 209 documents that we loaded in before. Let’s now go over the example of max marginal relevance. And so we’ll load in the text from the example where we have the information about mushrooms. For this example, we’ll create a small database that we can just use as a toy example. We’ve got our question, and now we can run a similarity search. We’ll set “k=2” to only return the two most relevant documents. And we can see that there is no mention of the fact that it is poisonous. Let’s now run it with MMR. While it’s passing “k=2”, we still want to return two documents, but let’s set “fetch_k=3”, where we fetch all three documents originally. We can now see that the information that is poisonous is returned among the documents that we retrieved. Let’s go back to one of the examples from the previous lesson when we asked about MATLAB and got back documents that had repeated information. To refresh your memory, we can take a look at the first two documents, just looking at the first few characters because they’re pretty long otherwise, and we can see that they’re the same. When we run MMR on these results, we can see that the first one is the same as before because that’s the most similar. But when we go on to the second one, we can see that it’s different. It’s getting some diversity in the responses. Let’s now move on to the self-query example. This is the one where we had the question, what did they say about regression in the third lecture? And it returned results from not just the third lecture, but also the first and the second. If we were fixing this by hand, what we would do is we’d specify a metadata filter. So we’d pass in this information that we want the source to be equal to the third lecture PDF. And then if we look at the documents that would be retrieved, they’d all be from exactly that lecture. We can use a language model to do this for us, so we don’t have to manually specify that. To do this, we’ll import a language model, OpenAI. We’ll import a retriever called the self-query retriever, and then we’ll import attribute info, which is where we can specify different fields in the metadata and what they correspond to. We only have two fields in the metadata, source and page. We fill out a description of the name, the description, and the type for each of these attributes. This information is actually going to be passed to the language model, so it’s important to make it as descriptive as possible. We’ll then specify some information about what’s actually in this document store. We’ll initialize the language model, and then we’ll initialize the self-query retriever using the “from_llm” method and passing in the language model, the underlying vector database that we’re going to query, the information about the description and the metadata, and then we’ll also pass in “verbose=True”. Setting “verbose=True” will let us see what’s going on underneath the hood when the LLM infers the query that should be passed along with any metadata filters. When we run the self-query retriever with this question, we can see, thanks to “verbose=True”, that we’re printing out what’s going on under the hood. We get a query of regression, this is the semantic bit, and then we get a filter where we have a comparator of equals between the source attribute and a value of docs and then this path, which is the path to the third machine learning lecture. So this is basically telling us to do a lookup in the semantic space on regression and then do a filter where we only look at documents that have a source value of this value. And so if we loop over the documents and print out the metadata, we should see that they’re all from this third lecture. And indeed they are. So this is an example where the self-query retriever can be used to filter exactly on metadata. A final retrieval technique that we can talk about is contextual compression. And so let’s load in some relevant modules here, the contextual compression retriever and then an LLM chain extractor. And what this is going to do is this is going to extract only the relevant bits from each document and then pass those as the final return response. We’ll define a nice little function to pretty print out docs because they’re often long and confusing and this will make it easier to see what’s going on. We can then create a compressor with the LLM chain extractor and then we can create the contextual compression retriever passing in the compressor and then the base retriever of the vector store. When we now pass in the question, what did they say about MATLAB and we look at the compressed docs, if we look at the documents we get back, we can see two things. One, they are a lot shorter than the normal documents. But two, we’ve still got some of this repeated stuff going on and this is because under the hood we’re using the semantic search algorithm. This is what we solved by using MMR from earlier in this lesson. This is a good example of where you can combine various techniques to get the best possible results. In order to do that, when we’re creating the retriever from the vector database, we can set the search type to MMR. We can then rerun this and see that we get back a filtered set of results that do not contain any duplicate information. So far, all the additional retrieval techniques that we’ve mentioned build on top of a vector database. It’s worth mentioning that there’s other types of retrieval that don’t use a vector database at all and instead uses other more traditional NLP techniques. Here, we’re going to recreate a retrieval pipeline with two different types of retrievers, an SVM retriever and a TF-IDF retriever. If you recognize these terms from traditional NLP or traditional machine learning, that’s great. If you don’t, it’s also fine. This is just an example of some other techniques that are out there. There are plenty more besides these and I encourage you to go check out some of them. We can run through the usual pipeline of loading and splitting pretty quickly. And then both of these retrievers expose a from text method. One takes in an embedding module, that’s the SVM retriever, and the TF-IDF retriever just takes in the splits directly. Now we can use the other retrievers. Let’s pass in what did they say about MATLAB to the SVM retriever and we can look at the top document we get back and we can see that it mentions a lot of stuff about MATLAB, so it’s picking up some good results there. We can also try this out on the TF-IDF retriever and we can see that the results look a little bit worse. Now’s a good time to pause and try out all these different retrieval techniques. I think you’ll notice that some of them are better than others at various things. And so I’d encourage you to try it out on a wide variety of questions. The self query retriever in particular is my favorite. So I would suggest trying that out with more and more complex metadata filters. Even maybe making up some metadata where there’s really nested metadata structures and you can try to get the LLM to infer that. I think that’s a lot of fun. I think that’s some of the more advanced stuff out there and so I’m really excited to have been able to share it with you. Now that we’ve talked about retrieval, we’re going to talk about the next step in the process, which is using these retrieved documents to answer the user question.
We’ve gone over how to retrieve documents that are relevant for a given question. The next step is to take those documents, take the original question, pass them both to a language model, and ask it to answer the question. We’re going to go over that in this lesson, and the few different ways that you can accomplish that task. Let’s jump in. In this lesson, we’re going to cover how to do question answering with the documents that you’ve just retrieved. This comes after we’ve done the whole storage and ingestion, after we’ve retrieved the relevant splits. Now we need to pass that into a language model to get to an answer. The general flow for this goes, the question comes in, we look up the relevant documents, we then pass those splits along with a system prompt and the human question to the language model and get the answer. By default, we just pass all the chunks into the same context window, into the same call of the language model. However, there are a few different methods we can use that have pros and cons to that. Most of the pros come from the fact that sometimes there can be a lot of documents and you just simply can’t pass them all into the same context window. MapReduce, Refine, and MapRerank are three methods to get around this issue of short context windows, and we’ll cover a few of them in the lesson today. Let’s get to coding! First, we’re going to load in our environment variables, as usual. We will then load in our vector database that was persisted from before. And I’m going to check that it is correct. And we can see that it has the same 209 documents from before. We do a quick little check of similarity search just to make sure it’s working for this first question of, what are major topics for this class? Now, we initialize the language model that we’re going to use to answer the question. We’re going to use the chat open AI model, GPT 3.5, and we’re going to set temperature equal to zero. This is really good when we want factual answers to come out, because it’s going to have a low variability and usually just give us the highest fidelity, most reliable answers. We’re then going to import the retrieval QA chain. This is doing question answering backed by a retrieval step. We can create it by passing in a language model, and then the vector database as a retriever. We can then call it with the query being equal to the question that we want to ask. And then when we look at the result, we get an answer. The major topic for this class is machine learning. Additionally, the class may cover statistics and algebra as refreshers in the discussion sections. Later in the quarter, the discussion sections will also cover extensions for the material taught in the main lectures. Let’s try to understand a little bit better what’s going on underneath the hood and expose a few of the different knobs that you can turn. The main part that’s important here is the prompt that we’re using. This is the prompt that takes in the documents and the question and passes it to a language model. For a refresher on prompts, you can see the first class that I did with Andrew. Here we define a prompt template. It has some instructions about how to use the following pieces of context, and then it has a placeholder for a context variable. This is where the documents will go, and a placeholder for the questions variable. We can now create a new retrieval QA chain. We’re going to use the same language model as before and the same vector databases as before, but we’re going to pass in a few new arguments. We’ve got the return source document, so we’re going to set this equals to true. This will let us easily inspect the documents that we retrieve. Then we’re also going to pass in a prompt equals to the QA chain prompt that we defined above. Let’s try out a new question. Is probability a class topic? We get back a result, and if we inspect what’s inside it, we can see, yes, probability is assumed to be a prerequisite for the class. The instructor assumes familiarity with basic probability and statistics, and we’ll go over some of the prerequisites in the discussion sections as a refresher course. Thanks for asking. It was very nice when it responded to us as well. For a little bit better intuition as to where it’s getting this data from, we can take a look at some of the source documents that were returned. If you look through them, you should see that all the information that was answered is in one of these source documents. Now’s a good time to pause and play around with a few different questions or a different prompt template of your own and see how the results change. So far, we’ve been using the stuff technique, the technique that we use by default, which basically just stuffs all the documents into the final prompt. This is really good because it only involves one call to the language model. However, this does have the limitation that if there’s too many documents, they may not all be able to fit inside the context window. A different type of technique that we can use to do question answering over documents is the map-reduce technique. In this technique, each of the individual documents is first sent to the language model by itself to get an original answer. And then those answers are composed into a final answer with a final call to the language model. This involves many more calls to the language model, but it does have the advantage in that it can operate over arbitrarily many documents. When we run the previous question through this chain, we can see another limitation of this method. Or actually, we can see two. One, it’s a lot slower. Two, the result is actually worse. There is no clear answer on this question based on the given portion of the document. This may occur because it’s answering based on each document individually. And so, if there is information that’s spread across two documents, it doesn’t have it all in the same context. This is a good opportunity to use the LangChain platform to get a better sense for what’s going on inside these chains. We’re going to demonstrate this here. And if you’d like to use it yourself, there’ll be instructions in the course material as to how you can get an API key. Once we’ve set these environment variables, we can rerun the MapReduce chain. And then we can switch over to the UI to see what’s going on underneath the hood. From here, we can find the run that we just ran. We can click in it, and we can see the input and the output. We can then see the child runs for a good analysis of what’s happening underneath the hood. First, we have the MapReduce documents chain. This actually involves four separate calls to the language model. If we click in to one of these calls, we can see that we have the input and the output for each of the documents. If we go back, we can then see that after it’s run over each of these documents, it’s combined in a final chain, the Stuffed Documents chain, where it stuffs all these responses into the final call. Clicking into that, we can see that we’ve got the system message, where we’ve got four summaries from the previous documents, and then the user question, and then we have the answer right there. We can do a similar thing, setting the chain type to Refine. This is a new type of chain, so let’s see what it looks like under the hood. Here we can see that it’s invoking the Refine Documents chain, which involves four sequential calls to an LLM chain. Let’s take a look at the first call in this chain to see what’s going on. Here we’ve got the prompt right before it’s sent to the language model. We can see a system message that’s made up of a few bits. This piece, context information is below, is part of the system message, part of the prompt template that we defined ahead of time. This next bit, all this text here, this is one of the documents that we retrieved. We’ve then got the user question down here, and then we’ve got the answer right here. If we then go back, we can look at the next call to the language model. Here the final prompt that we send to the language model is a sequence that combines the previous response with new data, and then asks for an improved response. We can see here that we’ve got the original user question, we’ve then got the answer, this is the same one as before, and then we’re saying we have the opportunity to refine the existing answer, only if needed, with some more context below. This is part of the prompt template, part of the instructions. The rest of this is the document that we retrieved, the second document in the list. We can see at the end we have some more instructions, given the new context, refined the original answer to better answer the question. And then down below, we get a final answer. But this is only the second final answer, and so this runs four times, this runs over all the documents before it arrives at the final answer. And that final answer is right here. The class assumes familiarity with basic probability and statistics, but we’ll have review sections to refresh the prerequisites. You’ll notice that this is a better result than the MapReduce chain. That’s because using the refined chain does allow you to combine information, albeit sequentially, and it actually encourages more carrying over of information than the MapReduce chain. This is a good opportunity to pause, try out some questions, try out some different chains, try out some different prompt templates, see what it looks like in the UI. There’s a lot to play around with here. One of the great things about chatbots and why they’re becoming so popular is that you can ask follow-up questions. You can ask for clarification about previous answers. So, let’s do that here. Let’s create a QA chain. We’ll just use the default stuff. Let’s ask it a question, is probability a class topic? And then let’s ask it a follow-up question. It mentions that probability should be a prerequisite, and so let’s ask, why are those prerequisites needed? And then we get back an answer. The prerequisites for the class are assumed to be basic knowledge of computer science and basic computer skills and principles. That doesn’t relate at all to the answer before where we were asking about probability. What’s going on here? Basically, the chain that we’re using doesn’t have any concept of state. It doesn’t remember what previous questions or previous answers were. For that, we’ll need to introduce memory, and that’s what we’ll cover in the next section.
We’re so close to having a functional chatbot. We started with loading documents, then we split them, then we created a vector store, we talked about different types of retrieval, we’ve shown that we can answer questions, but we just can’t handle follow-up questions, we can’t have a real conversation with it. The good news is, we’re going to fix that in this lesson. Let’s figure out how. We’re now going to finish up by creating a question answering chatbot. What this is going to do is, it’s going to look very similar to before, but we’re going to add in this concept of chat history. And this is any previous conversations or messages that you’ve exchanged with the chain. What that’s going to allow it to do, is it’s going to allow it to take that chat history into context when it’s trying to answer the question. So if you’re asking a follow-up question, it’ll know what you’re talking about. An important thing to note here is that all the cool types of retrieval that we talked about up to this point, like self-query or compression or anything like that, you can absolutely use them here. All the components we talked about are very modular and can fit together nicely. We’re just adding in this concept of chat history. Let’s see what it looks like. First, as always, we’re going to load our environment variables. If you have the platform set up, it might also be nice to turn it on from the beginning. There’ll be a lot of cool things that we’ll want to see what’s going on under the hood. We’re going to load our vector store that has all the embeddings for all the class materials. We can run through basic similarity search on the vector store. We can initialize the language model that we’re going to use as our chatbot. And then, and this is all from before, which is why I’m skimming through it so quickly. We can initialize a prompt template, create a retrieval QA chain, and then pass in a question and get back a result. But now let’s do more. Let’s add some memory to it. So we’re going to be working with conversation buffer memory. And what this does is it’s just going to simply keep a list, a buffer of chat messages in history, and it’s going to pass those along with the question to the chatbot every time. We’re going to specify memory key, chat history. This is just going to line it up with an input variable on the prompt. And then we’re going to specify return messages equal true. This is going to return the chat history as a list of messages as opposed to a single string. This is the simplest type of memory. For a more in-depth look at memory, go back to the first class that I taught with Andrew. We covered it in detail then. Let’s now create a new type of chain, the conversational retrieval chain. We pass in the language model, we pass in the retriever, and we pass in memory. The conversational retrieval chain adds a new bit on top of the retrieval QA chain, not just memory. Specifically, what it adds is it adds a step that takes the history and the new question and condenses it into a stand-alone question to pass to the vector store to look up relevant documents. We’ll take a look at this in the UI after we run it and see what effect it has. But for now, let’s try it out. We can ask a question. This is without any history, and see the result we get back. And then we can ask a follow-up question to that answer. This is the same as before. So we’re asking, is probability a class topic? We get some answer. The instructor assumes that students have basic understanding of probability and statistics. And then we ask, why are those prerequisites needed? We get back a result, and let’s take a look at it. We get back an answer, and now we can see that the answer is referring to basic probability and statistics as prerequisites and expanding upon that, not getting confused with computer science as it had before. Let’s take a look at what’s going on under the hood in the UI. So here, we can already see that there’s a bit more complexity. We can see that the input to the chain now has not only the question, but also chat history. Chat history is coming from the memory, and this gets applied before the chain is invoked and logged in this logging system. If we look at the trace, we can see that there’s two separate things going on. There’s first a call to an LLM, and then there’s a call to the stuff documents chain. Let’s take a look at the first call. We can see here a prompt with some instructions. Given the following conversation, a follow-up question, rephrase the follow-up question to be a stand-alone question. Here, we have the history from before. So we have the question we asked first, is probability a class topic? We then have the assistance answers. And then out here, we have the stand-alone question. What is the reason for requiring basic probability and statistics as prerequisites for the class? What happens is that stand-alone answer is then passed into the retriever, and we retrieve four documents or three documents or however many we specify. We then pass those documents to the stuff documents chain and try to answer the original question. So if we look into that, we can see that we have the system answer, use the following pieces of context to answer the user’s question. We’ve got a bunch of context. And then we have the stand-alone question down below. And then we get an answer. And here’s the answer that is relevant for the question at hand, which is about probability and statistics as prerequisites. This is a good time to pause and try out different options for this chain. You can pass in different prompt templates, not only for answering the question, but also for rephrasing that into a stand-alone question. You can try different types of memory, lots of different options to pull out here. After this, we’re going to put it all together in a nice UI. There’s going to be a lot of code for creating this UI, but this is the main important bit right here. Specifically, this is a full walkthrough of basically this whole class. So we’re going to load a database and retriever chain. We’re going to pass in a file. We’re going to load it with the PDF loader. We’re then going to load it into documents. We’re going to split those documents. We’re going to create some embeddings and put it in a vector store. We’re then going to turn that vector store into a retriever. We’re going to use similarity here with some “search_kwargs=k”, which we’re going to set equal to a parameter that we can pass in. And then we’re going to create the conversational retrieval chain. One important thing to note here is that we’re not passing in memory. We’re going to manage memory externally for the convenience of the GUI below. That means that chat history will have to be managed outside the chain. We then have a lot more code here. We’re not going to spend too much time on it, but pointing out that here we’re passing in chat history into the chain. And again, that’s because we don’t have memory attached to it. And then here we’re extending chat history with the result. We can then put it all together and run this to get a nice UI through which we can interact with our chatbot. Let’s ask it a question. Who are the TAs? The TAs are Paul Baumstarck, Catie Chang. You’ll notice here that there’s a few tabs that we can also click on to see other things. So if we click on the database, we can see the last question we asked of the database, as well as the sources we got back from the lookup there. So these are the documents. These are after the splittings happened. These are each chunk that we’ve retrieved. We can see the chat history with the input and the output. And then there’s also a place to configure it where you can upload files. We can also ask follow-ups. So let’s ask, what are their majors? And we get back an answer about the previously mentioned TAs. So we can see that Paul is studying machine learning and computer vision, while Catie is actually a neuroscientist. This is basically the end of the class. So now’s a great time to pause, ask it a bunch more questions, upload your own documents here, and enjoy this end-to-end question answering bot, complete with an amazing notebook UI. And that brings this class on LangChain, chat with your data, to an end. In this class, we’ve covered how to use LangChain to load data from a variety of document sources using LangChain’s 80-plus different document loaders. From there, we split the documents into chunks and talk about a lot of the nuances that arrive when doing so. After that, we take those chunks, create embeddings for them, and put them into a vector store, showing how that easily enables semantic search. But we also talk about some of the downsides of semantic search and where it can fail on the certain edge cases that arise. The next thing that we cover is retrieval, maybe my favorite part of the class, where we talk about a lot of new and advanced and really fun retrieval algorithms for overcoming those edge cases. We combine that with LLMs in the next session, where we take those retrieved documents, we take the user question, we pass it to an LLM, and we generate an answer to the original question. But there’s still one thing missing, which is the conversational aspect of it. And that’s where we finish out the class, by creating a fully functioning end-to-end chatbot over your data. I’ve really enjoyed teaching this class. I hope you guys have enjoyed taking it. And I want to thank everyone in the open source who has contributed a lot of the things that make this class possible, like all the prompts and a lot of the functionality that you see. As you guys build with LangChain and discover new ways of doing things and new tips and techniques, I hope that you share what you’ll learn on Twitter or even open up a PR in LangChain. It’s a really fast-moving field, and it’s an exciting time to be building. Look forward to seeing everything.
And that brings this class on LangChain, Chat with Your Data, to an end. In this class, we’ve covered how to use LangChain to load data from a variety of document sources using LangChain’s 80-plus different document loaders. From there, we split the documents into chunks, and talk about a lot of the nuances that arrive when doing so. After that, we take those chunks, create embeddings for them, and put them into a vector store, showing how that easily enables semantic search. But we also talk about some of the downsides of semantic search, and where it can fail in the certain edge cases that arise. The next thing that we cover is retrieval, maybe my favorite part of the class, where we talk about a lot of new and advanced and really fun retrieval algorithms for overcoming those edge cases. We combine that with LLMs in the next session, where we take those retrieved documents, we take the user question, we pass it to an LLM, and we generate an answer to the original question. But there’s still one thing missing, which is the conversational aspect of it. And that’s where we finish out the class, by creating a fully functioning end-to-end chatbot over your data. I’ve really enjoyed teaching this class. I hope you guys have enjoyed taking it. And I want to thank everyone in the open source who has contributed a lot of the things that make this class possible, like all the prompts and a lot of the functionality that you see. As you guys build with LangChain and discover new ways of doing things and new tips and techniques, I hope that you share what you’ll learn on Twitter or even open up a PR in LangChain. It’s a really fast-moving field, and it’s an exciting time. I really look forward to seeing how you apply everything that you learned in this class.