Here’s the problem: every time I start a new Claude Code session (or Claude or ChatGPT), it’s a blank slate. It doesn’t know how I organize my notes. It doesn’t know my coding preferences. It doesn’t know that I have a massive collection of PDFs sitting in my Obsidian vault. It’s like having a brilliant assistant who gets amnesia every morning. (View Highlight)
The Solution: CLAUDE.md
The magic happens with a single file called CLAUDE.md that lives in my Obsidian vault. Claude Code automatically reads this file at the start of every session, giving it context about who I am and how I work.
This file tells Claude:
• How my Obsidian vault is organized
• My coding style preferences (like using Go’s any instead of interface{})
• Where to find specific types of information
• How to interact with my note-taking system
• Custom commands and workflows I’ve developed (View Highlight)
One of the coolest parts of this setup is teaching Claude to search through everything in my Obsidian vault - including PDFs. I’ve configured it to use macOS’s Spotlight (mdfind) to search not just my markdown notes but also all those research papers, scanned documents, and random PDFs I’ve collected over the years.
mdfind -onlyin ~/Documents/mauricio “quantum computing”
Claude can now search through years of accumulated PDFs - research papers, scanned receipts, documentation, random articles I’ve saved. And with textutil, it can extract text from practically any document format:
textutil -convert txt interesting-paper.pdf -output - extracted.txt
No more “sorry, I can’t read that format.” Everything is searchable, everything is accessible. (View Highlight)
Daily Notes Without the Hassle
Instead of navigating folder structures, I just say “add this to my notes” and Claude knows exactly where today’s note lives (~/work log/2025/2025-08/2025-08-09.md). It creates the folder structure if needed, follows my naming conventions, and just works. (View Highlight)
Personalized Research
When I ask Claude to research a topic, it doesn’t just search the web. It knows my interests file, so when I ask about consensus algorithms, it focuses on Raft and Paxos (which I care about) rather than blockchain consensus (which I don’t). It’s like having a research assistant who’s read all my papers and knows my field. It even stores the results in my “research” folder. (View Highlight)
Finding That One PDF
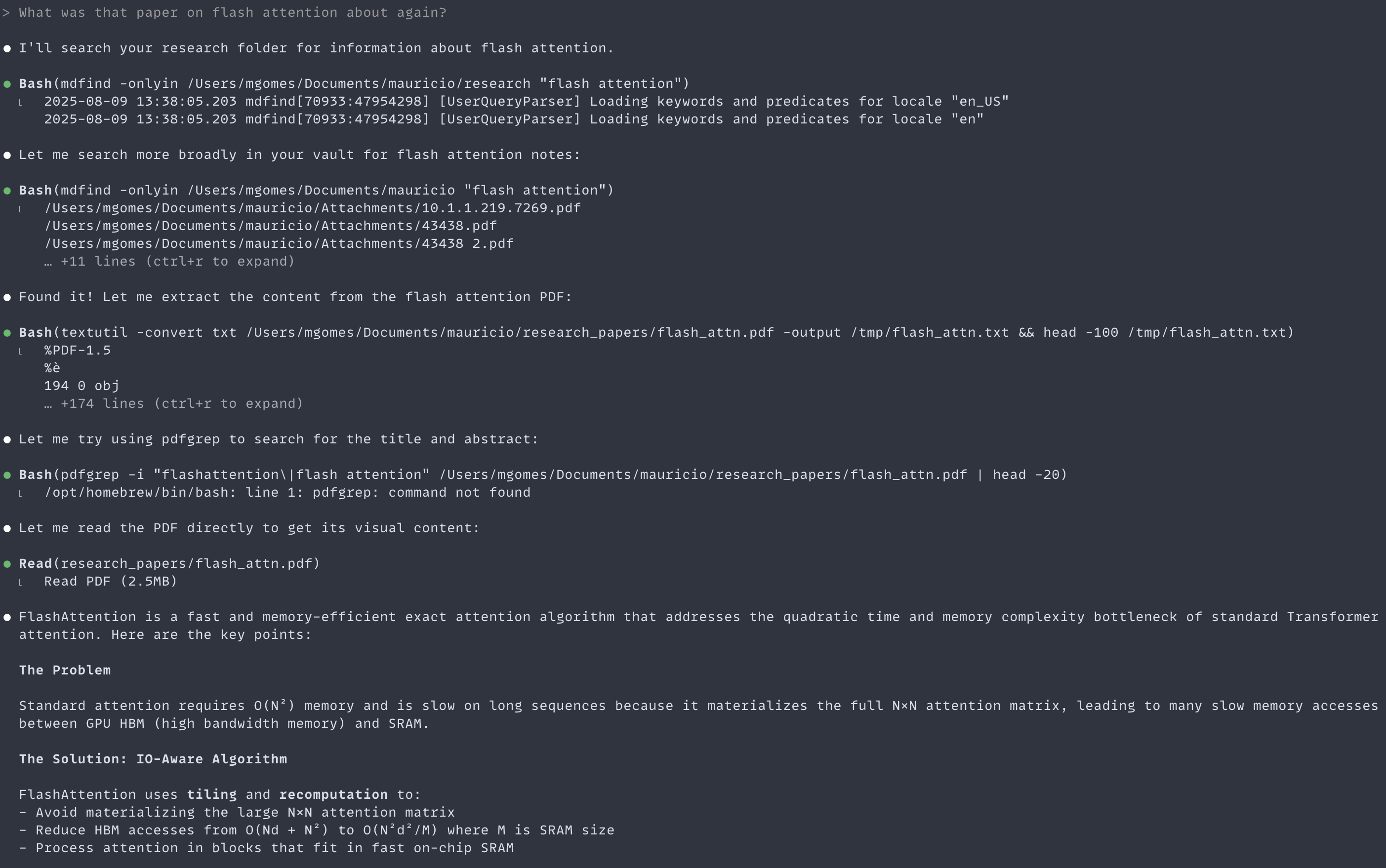
Remember that paper you scanned three years ago? The one about… something with quantum? Claude can find it:
(View Highlight)
The Technical Setup
Here’s what makes this work:
CLAUDE.md: Lives at the root of my Obsidian vault, automatically loaded by Claude Code
Context files: Stored in a special folder with my interests, preferences, and other personal data
Spotlight integration: All documents in the vault are indexed and searchable
Custom workflows: Defined in CLAUDE.md for common tasks
The beauty is its simplicity. No APIs, no complex integrations. Just markdown files and bash commands. (View Highlight)
Why This Matters
The real win isn’t just the productivity boost (though that’s nice). It’s the elimination of cognitive overhead. I don’t have to context-switch to “talking to a new AI” mode anymore.
Claude knows:
• My conventions and preferences
• Where everything lives
• What I care about
• How I like to work
Every conversation builds on the foundation of my entire knowledge base. It’s like having a brilliant assistant who’s also read everything you’ve ever written and remembers all your preferences. (View Highlight)
Building Your Own
Want to create your own personalized Claude Code setup? You’ll need:
An Obsidian vault (or similar knowledge base)
A CLAUDE.md file with your instructions and preferences
Some organizational system that makes sense to you
Optional: Lists of interests, collections, or other personal context
A system like macOS Spotlight that allows you to peek into documents of various types
The investment is maybe an hour of setup, but the compound returns are huge. Every session benefits from the accumulated context. (View Highlight)
I’m constantly adding to this setup. Some ideas I’m exploring:
• Integration with my calendar for time-aware context
• Direct access to meeting transcripts so I don’t always have to paste them in
• Connection to my code repositories for better programming assistance
• Reading my RSS feeds directly and plucking out articles it knows I will like
The foundation is solid, and that’s what matters. I’ve turned a brilliant but generic AI into something that actually understands my workflow and knowledge. (View Highlight)

 (View Highlight)
(View Highlight)