The success of Large Language Models (LLMs) has a lot to do with how they are trained. A common method is Masked Language Modeling (MLM), where the model is given text with some words “masked out”, and is tasked with guessing what the missing words are. “Guessing” means assigning a probability to all of the words or tokens in their vocabulary, indicating how likely they are to be the missing ones. (View Highlight)
In order to solve this problem, the model needs to understand the structure of the input text, the meanings of words, common references and conventions used in speaking and writing, and so on. In short, it needs a lot of the understanding that humans use when communicating — or at least the ability to simulate it. (View Highlight)
But language alone doesn’t solve all problems. Ask a LLM, “what is two plus two?” A lot of the time it will tell you that the answer is four. But maybe sometimes it won’t. There is nothing in a basic LLM that solves this mathematical problem directly. There are no internal registers containing the summands, and no process that would apply an algorithm to add them up. If the LLM gets the answer right, it’s because the model has picked up on patterns in its training data, and is managing to apply them correctly. (View Highlight)
Of course in a modern agent-based AI system, the LLM would recognize the request for a simple mathematical calcualtion, and would invoke a tool to get the answer. But the LLM by itself does not do that. The LLM understands numbers as text, but it would be better if it understood them as numbers. (View Highlight)
The western side looks like part of a parallelogram. But there is this lump in the northeast corner, that makes its way down to an indentation on the eastern side, with a few weird peninsulas sticking out. Then there is this big hook thing on the southeast, and a couple of disconnected blobs down below that.
If one gave that description to a LLM, would it have a good understanding of what Massachusetts looks like? Not really. Text alone does not do a good job of representing spatial data. If we really want to leverage a LLM’s “reasoning” capabilities, we need to describe spatial objects in a way that the model understands. (View Highlight)
When you scratch the surface of a LLM, it doesn’t really understand text either. It understands vectors of numbers representing text tokens. So the first step of interaction with a LLM is to replace your text tokens with vector “embeddings”.
The most successful embeddings are constructed so that mathematical relationships between the vectors correspond to semantic relationships among the words. That makes it relatively easy to train a model to understand those relationships. (View Highlight)
If we want a model to understand geospatial objects, we need something similar: a geometric encoding that represents objects as a vectors. A further requirement is that all such encodings need to be the same size, regardless of the type and complexity of each object being encoded. That way we can stack encodings for multiple objects in the same way that we stack embeddings for a string of text tokens. (View Highlight)
A handy method is Multi-Point Proximity (MPP) encoding, which I described in other blog posts, as well as in a research paper that you might find interesting. Basically you lay out a grid of reference points, and compute the distance of a shape to each of them. After applying some scaling, you have a vector that approximately encodes the object’s geometric properties. Any shape that uses the same set of reference points has the same size, so you can stack up encodings for any number of objects in a region of interest. (View Highlight)
The discussion above establishes some similarities between text processing and geospatial analysis.
Zoom image will be displayed
(View Highlight)
One might ask whether there is some kind of geospatial operation corresponding to Masked Language Modeling. There is! Just like training a model to predict masked words based on the words around them, we can train a model to predict the types of “masked” geospatial entities based on what else in in the vicinity. Call it Maksed Geospatial Modeling (MGM).
Zoom image will be displayed
(View Highlight)
On the left we have a typical MLM task. A model sees the tokens, along with their positional encodings, with one of the tokens replaced by a mask. It predicts a probability distribution for the missing word. Here, the most probable missing word might be “walk”. But “bus” might work in some situations. Most of the other words in the language (“coffee”) would have probabilities near zero, as they don’t make much sense in the given context.
The right shows the geospatial equivalent. We have a bunch of entities in the region, most of which have a known label, like roadways of different types, rivers, ponds, etc. One entity is masked out. Its label is not revealed to the model, and the model’s task is to guess what it might be. A MGM would compute a probability distribution over possible labels. During training, the MGM learns to recognize features and spatial relationships that give hints abut an object’s type. Here we have a polygon, so immediately any roadway label makes little sense, as they are more linear. And this polygon has no roads intersecting it, making it unlikely to represent say a residential or commercial district. A well trained model would guess that the most probable label is “lakes and ponds”, which would be correct in this case. (View Highlight)
I recently built a simple MGM using geospatial features from OpenStreetMap for a few cities and towns in the northeastern United States. A full description of the procedures and models are given in another blog post, but I’ll repeat the key points here. (View Highlight)
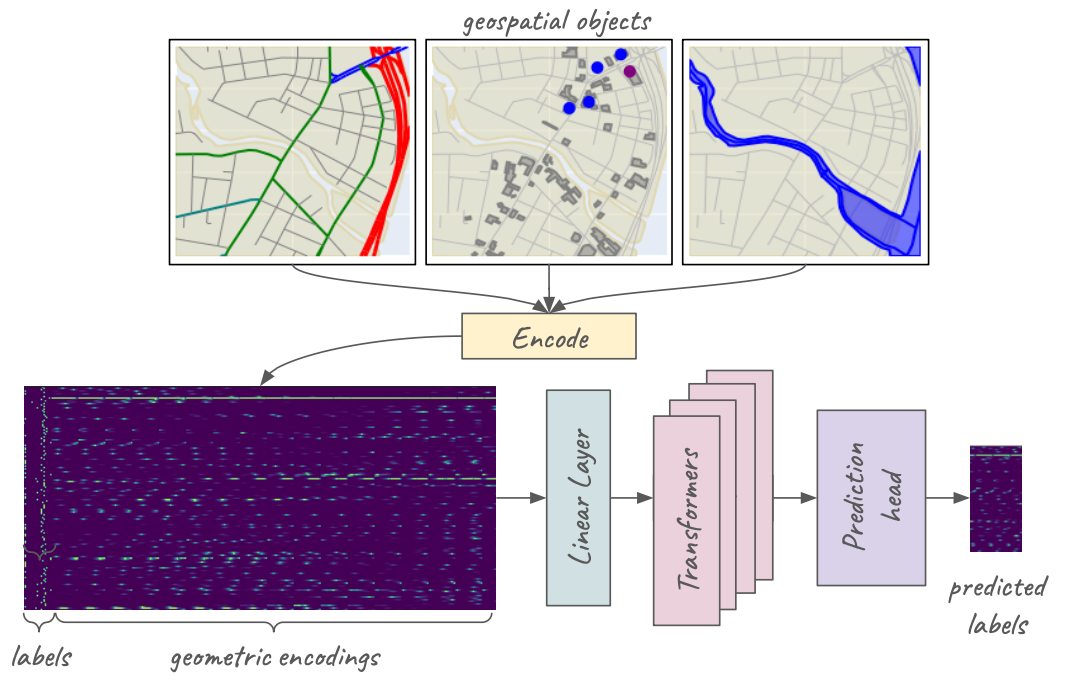
The model used 22 types of features, consisting of roads of different types, railway features, water features, types of districts (residential, commercial, etc), and certain types of amentities (parking lots, restaurants, etc.) I extracted features for about 19,000 1km x 1km tiles, and split them into training and validation sets. The data for each geospatial entity consisted of a one-hot vector indicating its label, concatenated with its MPP encoding within the tile. Vectors for all entities in a tile were stacked, creating a data matrix (illustrated by the dark blue rectangle on the lower left).
Zoom image will be displayed
Data and processing for a Masked Geospatial Model (MGM). (View Highlight)
For a sample of entities in any tile, I masked the label (i.e. replaced it with a zero-hot vector). The model was tasked to guess the missing labels. The architecture is a four-layer transformer with a prediction head yielding logits for the 22 possible class labels. The model was trained using cross-entropy loss for the masked labels from the training set. (View Highlight)
We have built a Masked Geospatial Model that shows decent performance. But the MGM itself isn’t the point. The important parts are the problems that were solved in order to make it work, and implications for further development.
To make it work, we needed a way to represent geospatial objects — roads, lakes, districts, and so on — in the same way that text models represent tokens. Specifically we needed consistently sized vectors that encode any point, line, or polygon with enough fidelity that a neural network can make sense of them. That was accomplished with MPP encoding, proving it to be a promising method enabling geospatial ML/AI for vector-mode data. (View Highlight)
The fact that the model works at all suggests that LLM-style transformer processing has enormous potential for geospatial analysis. The architecture works for text processing because a stack of transformer layers captures relationships among combinations of its input tokens. This is crucial for understanding text, where the meaning of one word may depend on several other words in the sentence.
Similarly in geospatial analysis, the nature of an entity — such as a segment of a major street — depends on what is around it. For various problems, one may want to know whether it is near residential or commercial districts, lies in a business district, is near recreational facilities, and so on. Transformer processing can capture such relationships. (View Highlight)
The MGM performs well because it implicitly understands concepts like connectivity, proximity, intersection, overlap; and is able to associate patterns of those properties with specific geospatial entity types.
More importantly, the model encodes that understanding in its internal representations. While we may not be particularly interested in guessing whether something is a road or a lake, the encoded knowledge can be used for other problems, such as business site selection, providing tourist information, planning a new development, or any other problem requiring regional geospatial understanding. (View Highlight)
In short, Masked Geospatial Modeling offers the potential for building foundation models using vector-mode geospatial data. (View Highlight)
 (View Highlight)
(View Highlight)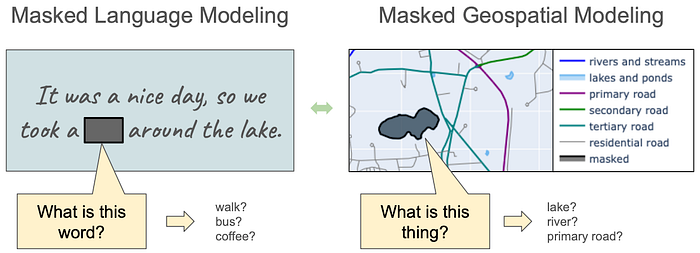 (View Highlight)
(View Highlight)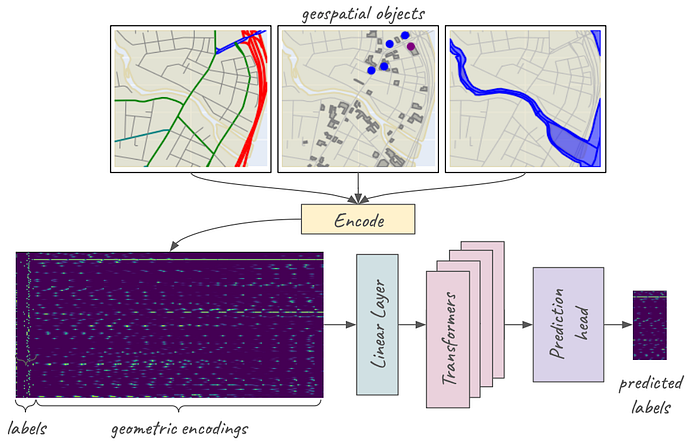 Data and processing for a Masked Geospatial Model (MGM). (View Highlight)
Data and processing for a Masked Geospatial Model (MGM). (View Highlight)