Given how much energy, literal and figurative, goes into developing new AIs, we have a surprisingly hard time measuring how “smart” they are, exactly. The most common approach is to treat AI like a human, by giving it tests and reporting how many answers it gets right. There are dozens of such tests, called benchmarks, and they are the primary way of measuring how good AIs get over time. (View Highlight)
First, many benchmarks and their answer keys are public, so some AIs end up incorporating them into their basic training, whether by accident or so they can score highly on these benchmarks. But even when that doesn’t happen, it turns out that we often don’t know what these tests really measure. For example, the very popular MMLU-Pro benchmark includes questions like “What is the approximate mean cranial capacity of Homo erectus?” and “What place is named in the title of the 1979 live album by rock legends Cheap Trick?” with ten possible answers for each. What does getting this right tell us? I have no idea. And that is leaving aside the fact that tests are often uncalibrated, meaning we don’t know if moving from 84% correct to 85% is as challenging as moving from 40% to 41% correct. And, on top of all that, for many tests, the actual top score may be unachievable because there are many errors in the test questions and measures are often reported in unusual ways. (View Highlight)
Despite these issues, all of these benchmarks, taken together, appear to measure some underlying ability factor. And higher-quality benchmarks like ARC-AGI and METR Long Tasks show the same upward, even exponential, trend. This matches tests of the real-world impact of AI across industries that suggest that this underlying increase in “smarts” translates to actual ability in everything from medicine to finance. (View Highlight)
To figure this out for yourself, you are going to need to interview your AI. (View Highlight)
If benchmarks can fail us, sometimes “vibes” can succeed. If you work with enough AI models, you can start to see the difference between them in ways that are hard to describe, but are easily recognizable. As a result, some people who use AI a lot develop idiosyncratic benchmarks to test AI ability. For example, Simon Willison asks every model to draw a pelican on a bike, and I ask every image and video model to create an otter on a plane. While these approaches are fun, they also give you a sense of the AI’s understanding of how things relate to each other, its “world model.” And I have dozens of others, like asking AIs to create JavaScript for “the control panel of a starship in the distant future” (you can see some older and new models doing that below) or to produce a challenging poem. I have the AI build video games and shaders and analyze academic papers. I also conduct tiny writing experiments, including questions of time travel. Each gives me some insight into how the model operates: Does it make many errors? Do its answers look similar to every other model? What are themes and biases that it returns to? And so on. (View Highlight)
Benchmarking through vibes - whether that is stories or code or otters - is a great way for an individual to get a feel for AI models, but it is also very idiosyncratic. The AI gives different answers every time, making any competition unfair unless you are rigorous. Plus, better prompts may result in better outcomes. Most importantly, we are relying on our feelings rather than real measures - but the obvious differences in vibes show that standardized benchmarks alone are not enough, especially when having a slightly better AI at a particular task actually matters. (View Highlight)
When companies choose which AI systems to use, they often view this as a technology and cost decision, relying on public benchmarks to ensure they are buying a good-enough model (if they use any benchmarks at all). This can be fine in some use cases, but quickly breaks down because, in many ways, AI acts more like a person, with strange abilities and weaknesses, than software. And if you use the analogy of hiring rather than technological adoption, then it is harder to justify the “good enough” approach to benchmarking. Companies spend a lot of money to hire people who are better than average at their job and would be especially careful if the person they are hiring is in charge of advising many others. A similar attitude is required for AI. You shouldn’t just pick a model for your company, you need to conduct a rigorous job interview. (View Highlight)
Interviewing an AI is not an easy problem, but it is solvable. Probably the best example of benchmarking for the real world has been OpenAI’s recent GDPval paper. The first step is establishing real tasks, which OpenAI did by gathering experts with an average of 14 years of experience in industries ranging from finance to law to retail and having them generate complex and realistic projects that would take human experts an average of four to seven hours to complete (you can see all the tasks here). The second step is testing the AIs against those tasks. In this case both multiple AI models and other human experts (who were paid by the hour) did each task. Finally, there is the evaluation stage. OpenAI had a third group of experts grade the results, not knowing which answers came from the AI and which from the human, a process which took over an hour per question. Taken together, this was a lot of work. (View Highlight)
As AI models get better at tasks and become more integrated into our work and lives, we need to start taking the differences between them more seriously. For individuals working with AI day-to-day, vibes-based benchmarking can be enough. You can just run your otter test. Though, in my case, otters on planes have gotten too easy, so I tried the prompt “The documentary footage from 1960s about the famous last concert of that band before the incident with the swarm of otters” in Sora 2 and got this impressive result. (View Highlight)
The work is worth it. You wouldn’t hire a VP based solely on their SAT scores. You shouldn’t pick the AI that will advise thousands of decisions for your organization based on whether it knows that the mean cranial capacity of Homo erectus is just under 1,000 cubic centimeters. (View Highlight)
But it also revealed where AI was strong (the best models beat humans in areas ranging from software development to personal financial advisors) and where it was weak (pharmacists, industrial engineers, and real estate agents easily beat the best AI). You can further see that different models performed differently (ChatGPT was a better sales manager, Claude a better financial advisor). So good benchmarks help you figure out the shape of what we called the Jagged Frontier of AI ability, and also track how it is changing over time. (View Highlight)
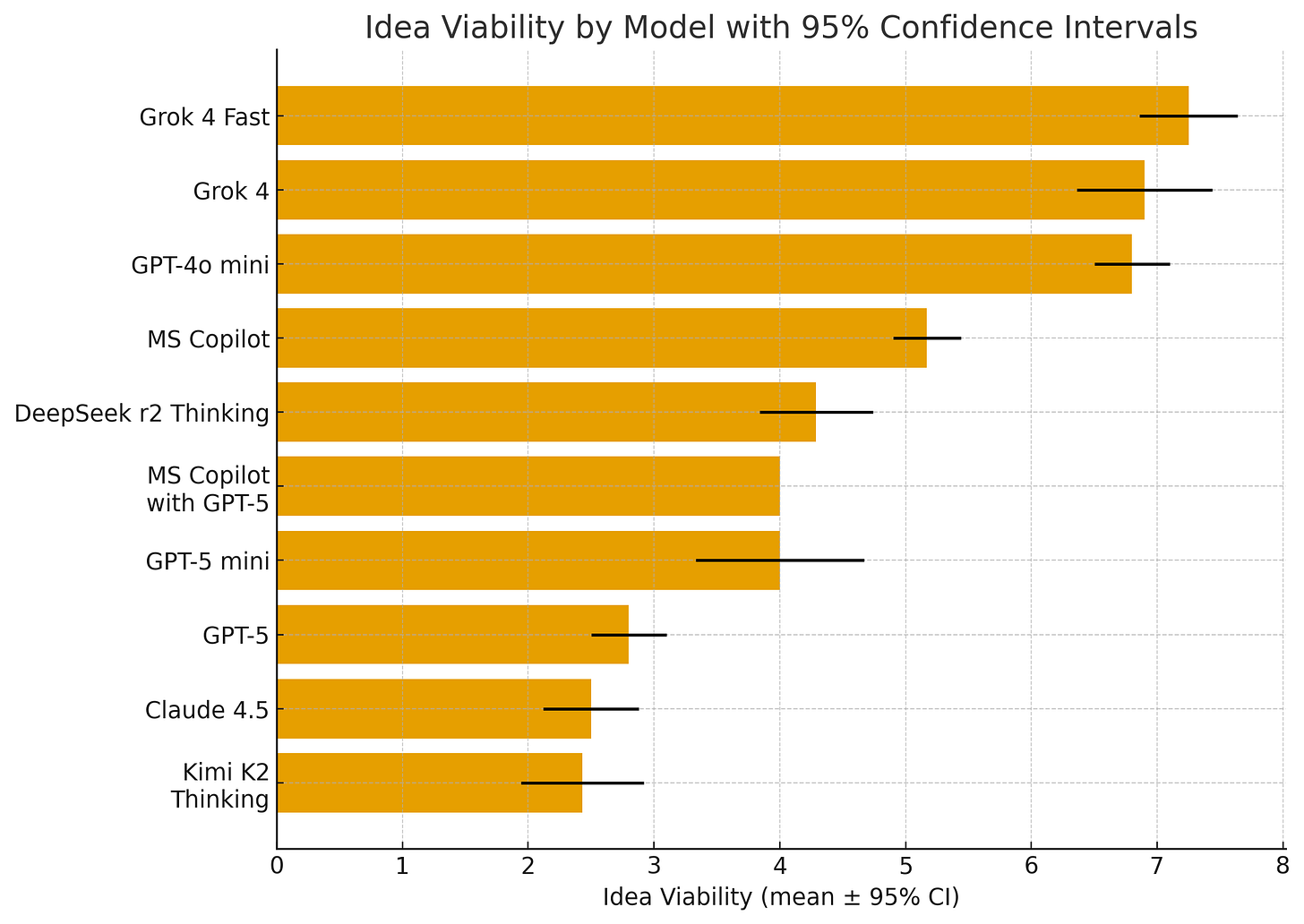
But even these tests don’t shed light on a key issue, which is the underlying attitude of the AI when it makes decisions. As one example of how to do this, I gave a number of AIs a short pitch for what I think is a dubious idea - a company that delivers guacamole via drones. I asked each AI model to rate, on a scale of 1-10, how viable GuacaDrone was ten times each (remember that AIs answer differently every time, so you have to do multiple tests). The individual AI models were actually quite consistent in their answers, but they varied widely from AI to AI. I would personally have rated this idea a 2 or less, but the models were kinder. Grok thought this was a great idea, and Microsoft Copilot was excited as well. Other models, like GPT-5 and Claude 4.5, were more skeptical. (View Highlight)
The differences aren’t trivial. When your AI is giving advice at scale, consistently rating ideas 3–4 points higher or lower means consistently steering you in a different direction. Some companies may want an AI that embraces risk, others might want to avoid it. But either way, it is important to understand how your AI “thinks” about critical business issues. (View Highlight)
But organizations deploying AI at scale face a different challenge. Yes, the overall trend is clear: bigger, more recent models are generally better at most tasks. But “better” isn’t good enough when you’re making decisions about which AI will handle thousands of real tasks or advise hundreds of employees. You need to know specifically what YOUR AI is good at, not what AIs are good at on average. (View Highlight)
That’s what the GDPval research revealed: even among top models, performance varies significantly by task. And the GuacaDrone example shows another dimension - when tasks involve judgment on ambiguous questions, different models give consistently different advice. These differences compound at scale. An AI that’s slightly worse at analyzing financial data, or consistently more risk-seeking in its recommendations, doesn’t just affect one decision, it affects thousands. (View Highlight)
You can’t rely on vibes to understand these patterns, and you can’t rely on general benchmarks to reveal them. You need to systematically test your AI on the actual work it will do and the actual judgments it will make. Create realistic scenarios that reflect your use cases. Run them multiple times to see the patterns and take the time for experts to assess the results. Compare models head-to-head on tasks that matter to you. It’s the difference between knowing “this model scored 85% on MMLU” and knowing “this model is more accurate at our financial analysis tasks but more conservative in its risk assessments.” And you are going to need to be able to do this multiple times a year, as new models come out and need evaluation. (View Highlight)

 (View Highlight)
(View Highlight)