I’ve been working on internal “AI” adoption, which is really LLM-tooling and agent adoption, for the past 18 months or so. This is a problem that I think is, at minimum, a side-quest for every engineering leader in the current era. Given the sheer number of folks working on this problem within their own company, I wanted to write up my “working notes” of what I’ve learned. (View Highlight)
The image provides instructions for triaging Jira tickets, detailing steps for retrieving comments, updating labels, and determining responsible teams. It includes guidelines for using Slack for communication and references, and lists teams with their on-call aliases and areas of responsibility. (View Highlight)
This isn’t a recommendation about what you should do, merely a recap of how I’ve approached the problem thus far, and what I’ve learned through ongoing iteration. I hope the thinking here will be useful to you, or at least validate some of what you’re experiencing in your rollout. The further you read, the more specific this will get, ending with cheap-turpentine-esque topics like getting agents to reliably translate human-readable text representations of Slack entities into mrkdwn formatting of the correct underlying entity. (View Highlight)
Imprint’s general approach to refining AI adoption is strategy testing: identify a few goals, pick an initial approach, and then iterate rapidly in the details until the approach genuinely works. In an era of crushing optics, senior leaders immersing themselves in the details is one of our few defenses.
(View Highlight)
Shortly after joining, I partnered with the executive team to draft the above strategy for AI adoption. After a modest amount of debate, the pillars we landed on were:
Pave the path to adoption by removing obstacles to adoption, especially things like having to explicitly request access to tooling. There’s significant internal and industry excitemetn for AI adoption, and we should believe in our teams. If they aren’t adopting tooling, we predominantly focus on making it easier rather than spending time being skeptical or dismissive of their efforts towards adoption.
Opportunity for adoption is everywhere, rather than being isolated to engineering, customer service, or what not. To become a company that widely benefits from AI, we need to be solving the problem of adoption across all teams. It’s not that I believe we should take the same approach everywhere, but we need some applicable approach for each team.
Senior leadership leads from the front to ensure what we’re doing is genuinely useful, rather than getting caught up in what we’re measuring. (View Highlight)
As you see from those principles, and my earlier comment, my biggest fear for AI adoption is that they can focus on creating the impression of adopting AI, rather than focusing on creating additional productivity. Optics are a core part of any work, but almost all interesting work occurs where optics and reality intersect, which these pillars aimed to support. (View Highlight)
My adoption step was collecting as many internal examples of tips and tricks as possible into a single Notion database. I took a very broad view on what qualified, with the belief that showing many different examples of using tools–especially across different functions–is both useful and inspiring.
(View Highlight)
One of my core beliefs in our approach is that making prompts discoverable within the company is extremely valuable. Discoverability solves four distinct problems:
Creating visibility into what prompt’s can do (so others can be inspired to use them in similar scenarios). For example, that you can use our agents to comment on a Notion doc when it’s created, respond in Slack channels effectively, triage Jira tickets, etc
Showing what a good prompt looks like (so others can improve their prompts). For example, you can start moving complex configuration into tables and out of lists which are harder to read and accurately modify
Serving as a repository of copy-able sections to reuse across prompts. For example, you can copy one of our existing “Jira-issue triaging prompts” to start triaging a new Jira project
Prompts are joint property of a team or function, not the immutable construct of one person. For example, anyone on our Helpdesk team can improve the prompt responding to Helpdesk requests, not just one person with access to the prompt, and it’s not locked behind being comfortable with Git or Github (although I do imagine we’ll end up with more restrictions around editing our most important internal agents over time)
Identifying repeating prompt sub-components that imply missing or hard to use tools. For example, earlier versions of our prompts had a lot of confusion around how to specify Slack users and channels, which I got comfortable working around, but others did not (View Highlight)
My core approach is that every agent’s prompt is stored in a single Notion database which is readable by everyone in the company. Most prompts are editable by everyone, but some have editing restrictions.
Here’s an example of a prompt we use for routing incoming Jira issues from Customer Support to the correct engineering team. (View Highlight)
Here’s a second example, this time of responding to requests in our Infrastructure Engineering team’s request channel.
(View Highlight)
In addition to collecting tips and prompts, the next obvious step for AI adoption is identifying a standard AI platform to be used within the company, e.g. ChatGPT, Claude, Gemini or what not.
We’ve gone with OpenAI for everyone. In addition to standardizing on a platform, we made sure account provisioning was automatic and in place on day one. To the surprise of no one who’s worked in or adjacent to IT, a lot of revolutionary general AI adoption is… really just account provisioning and access controls. These are the little details that can so easily derail the broader plan if you don’t dive into them.
Within Engineering, we also provide both Cursor and Claude. That said, the vast majority of our Claude usage is done via AWS Bedrock, which we use to power Claude Code… and we use Claude Code quite a bit. (View Highlight)
While there’s a general industry push towards adopting more AI tooling, I find that a significant majority of “AI tools” are just SaaS vendors that talk about AI in their marketing pitches. We have continued to adopt vendors, but have worked internally to help teams evaluate which “AI tools” are meaningful.
We’ve spent a fair amount of time going deep on integrating with AI tooling for chat and IVR tooling, but that’s a different post entirely. (View Highlight)
Measuring AI adoption is, like all measurement topics, fraught. Altogether, I’ve found measuring tool adoption very instruction to identify the right questions to ask. Why haven’t you used Cursor? Or Claude Code? Or whatever? These are fascinating questions to dig into. I try to look at usage data at least once a month, with a particular focus on two questions:
For power adopters, what are they actually doing? Why do they find it useful?
For low or non-adopters, why aren’t they using the tooling? How could we help solve that for them? (View Highlight)
At the core, I believe folks who aren’t adopting tools are rational non-adopters, and spending some time understanding the (appearance of) resistance goes further than top-down mandate. I think it’s often an education gap that is bridged easily enough. Conceivably, at some point I’ll discover a point of diminishing returns, where the lack of progress is stymied on folks who are rejecting AI tooling–or because the AI tooling isn’t genuinely useful–but I haven’t found that point yet. (View Highlight)
Building internal agents
The next few sections are about building internal agents. The core implementation is a single stateless lambda which handles a wide variety of HTTP requests, similar-ish to Zapier. This is currently implemented in Python, and is roughly 3,000 lines of code, much of it dedicated to oddities like formatting Slack messages, etc. (View Highlight)
For the record, I did originally attempt to do this within Zapier, but I found that Zapier simply doesn’t facilitate the precision I believe is necessary to do this effectively. I also think that Zapier isn’t particularly approachable for a non-engineering audience. (View Highlight)
As someone who spent a long time working in platform engineering, I still want to believe that you can build a platform, and users will come. Indeed, I think it’s true that a small number of early adopters will come, if the problem is sufficiently painful for them (View Highlight)
However, what we’ve found effective for driving adoption is basically the opposite of that. What’s really worked is the intersection of platform engineering and old-fashioned product engineering:
(product eng) find a workflow with a lot of challenges or potential impact
(product eng) work closely with domain experts to get the first version working
(platform eng) ensure that working solution is extensible by the team using it
(both) monitor adoption as indicator of problem-solution fit, or lack thereof (View Highlight)
Some examples of the projects where we’ve gotten traction internally:
• Writing software with effective AGENTS.md files guiding use of tests, typechecking and linting
• Powering initial customer questions through chat and IVR
• Routing chat bots to steer questions to solve the problem, provide the the answer, or notify the correct responder
• Issue triaging for incoming tickets: tagging them, and assigning them to the appropriate teams
• Providing real-time initial feedback on routine compliance and legal questions (e.g. questions which occur frequently and with little deviation)
• Writing weekly priorities updates after pulling a wide range of resources (Git commits, Slack messages, etc) (View Highlight)
For all of these projects that have worked, the formula has been the opposite of “build a platform and they will come.” Instead it’s required deep partnership from folks with experience building AI agents and using AI tooling to make progress. The learning curve for effective AI adoption in important or production-like workflows remains meaningfully high. (View Highlight)
Agents that use powerful tools represent a complex configuration problem. First, exposing too many tools–especially tools that the prompt author doesn’t effectively understand–makes it very difficult to create reliable workflows. For example, we have an exit_early command that allows terminating the agent early: this is very effective in many cases, but is also easy to break your bot. (View Highlight)
Similarly, we have a slack_chat command that allows posting across channels, which can support a variety of useful workflows (e.g. warm-handoffs of a question in one channel into a more appropriate alternative), but can also spam folks. Second, as tools get more powerful, they can introduce complex security scenarios. (View Highlight)
To address both of these, we currently store configuration in a code-reviewed Git repository. Here’s an example of a JIRA project.
This image shows a configuration script for a Jira setup with specified project keys, a prompt ID, a list of allowed tools such as “notion_search” and “slack_chat,” and a model set to “gpt-4.1”. The configuration also has a setting “respond_to_issue” set to False. (View Highlight)
Compared to a JSON file, we can statically type the configuration, and it’s easy to extend over time. For example, we might want to extend slack_chat to restrict which channels a given bot is allowed to publish into, which would be easy enough. For most agents today, the one thing not under Git-version control is the prompts themselves, which are versioned by Notion. However, we can easily require specific agents to use prompts within the Git-managed repository for sensitive scenarios.
After passing tests, linting and typechecking, the configurations are automatically deployed. (View Highlight)
The biggest internal opportunity that I see today is figuring out how to get non-engineers an experience equivalent to running Claude Code locally with all their favorite MCP servers plugged in. I’ve wanted ChatGPT or Claude.ai to provide this, but they don’t really quite get there, Claude Desktop is close, but is somewhat messy to configure as we think about finding a tool that we can easily allow everyone internally to customize and use on a daily basis.
I’m still looking for what the right tool is here. If anyone has any great suggestions that we can be somewhat confident will still exist in two years, and don’t require sending a bunch of internal data to a very early stage company, then I’m curious to hear! (View Highlight)
• We are still very early on AI adoption, so focusing on rate of learning is more valuable than anything else
• If you want to lead an internal AI initiative, you simply must be using the tools, and not just ChatGPT, but building your own tool-using agent using only an LLM API
• My experience is that real AI adoption on real problems is a complex blend of: domain context on the problem, domain experience with AI tooling, and old-fashioned IT issues. I’m deeply skeptical of any initiative for internal AI adoption that doesn’t anchor on all three of those. This is an advantage of earlier stage companies, because you can often find aspects of all three of those in a single person, or at least across two people. In larger companies, you need three different organizations doing this work together, this is just objectively hard
• I think model selection matters a lot, but there are only 2-3 models you need at any given moment in time, and someone can just tell you what those 2-3 models are at any given moment. For example, GPT-4.1 is just exceptionally good at following rules quickly. It’s a great model for most latency-sensitive agents (View Highlight)

 The image provides instructions for triaging Jira tickets, detailing steps for retrieving comments, updating labels, and determining responsible teams. It includes guidelines for using Slack for communication and references, and lists teams with their on-call aliases and areas of responsibility. (View Highlight)
The image provides instructions for triaging Jira tickets, detailing steps for retrieving comments, updating labels, and determining responsible teams. It includes guidelines for using Slack for communication and references, and lists teams with their on-call aliases and areas of responsibility. (View Highlight) (View Highlight)
(View Highlight)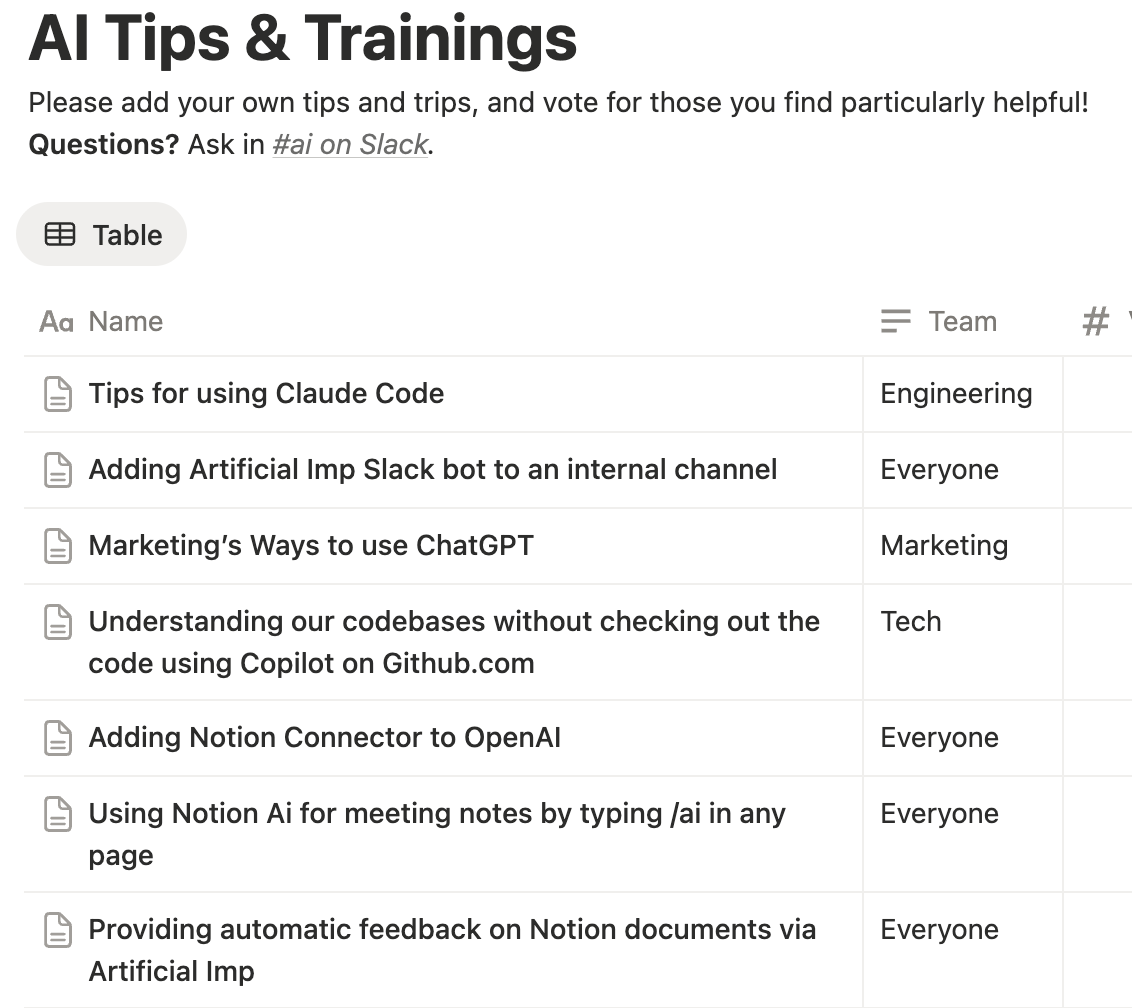 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight) This image shows a configuration script for a Jira setup with specified project keys, a prompt ID, a list of allowed tools such as “notion_search” and “slack_chat,” and a model set to “gpt-4.1”. The configuration also has a setting “respond_to_issue” set to False. (View Highlight)
This image shows a configuration script for a Jira setup with specified project keys, a prompt ID, a list of allowed tools such as “notion_search” and “slack_chat,” and a model set to “gpt-4.1”. The configuration also has a setting “respond_to_issue” set to False. (View Highlight)