Limits on the availability of real-world data may be less consequential if synthetic data (data generated by AI systems) can be used to improve the performance of subsequent models. Previous editions of the AI Index found no definitive evidence that synthetic data improves model performance during the pre-training phase.10 The 2024 report referenced research suggesting that model performance can collapse when real training data is replaced with synthetic data. The 2025 report noted more recent findings that such collapse can be avoided if real data remains part of the training set, but that simply adding more data does not necessarily lead to performance gains. (View Highlight)
The consensus remains largely unchanged. There is still no definitive evidence that synthetic data can fully offset real-data depletion in pre-training contexts. However, recent research suggests that synthetic data may offer value in more limited settings. Hybrid training approaches, which combine real and synthetic data, can significantly accelerate training, sometimes by a factor of five to 10 at scale, without surpassing real data in final model performance. Training on purely synthetic data has shown promise for smaller models or narrowly defined tasks, such as classification, code generation, or work in low-resource languages , but these gains have not generalized to large, general-purpose language models. Where synthetic-only training has achieved performance comparable to real data, it has typically involved substantially smaller models that are not directly comparable to current state-of-the-art systems. For example, the SYNTHLLM family of models, trained entirely on synthetic data, achieves strong results yet still lags behind leading models on major benchmarks (Figure 1.1.15). (View Highlight)
Discussions on data availability often overlook an important shift in recent AI research. Performance gains are increasingly driven by improving the quality of existing datasets, not by acquiring more. Rather than scaling data indiscriminately, researchers are spending more effort in pruning, curating, and refining training inputs. Data-centric methods emphasize performance improvements through practices such as cleaning labels, deduplicating samples, and constructing higher-quality datasets. A growing body of research shows that training models on low-quality or polluted data can significantly degrade performance. Likewise, recent evidence illustrates that data pruning, selecting the most informative training inputs, often outperforms approaches that train on all available data indiscriminately. (View Highlight)
Recent large-scale model development illustrates this paradigm in practice. Olmo3 researchers prioritized large-scale deduplication, quality-aware data selection, and stage-specific training curricula rather than indiscriminate data scaling. These interventions, combined with iterative feedback loops to evaluate and refine candidate data mixes, allowed their models to achieve competitive performance despite training on substantially fewer tokens than other leading state-of-the-art models (Figure 1.1.16). Olmo 3.1’s Think 32B model, for example, contains roughly 32 billion parameters, nearly 90 times fewer than Grok 4’ s 3 trillion, yet it achieves comparable performance on several benchmarks, including American Invitational Mathematics Examination (AIME)11 2025. (View Highlight)
Recent research shows that synthetically generated data can be effective for improving model performance in post-training settings, including fine-tuning, alignment, instruction tuning, and reinforcement learning. A growing body of research released in 2025 supports this finding. Evidence suggests that synthetic post-training data is effective in few-shot generation settings , for improving long-context capabilities, for optimizing reinforcement learning workflows, and for strengthening reasoning more broadly. (View Highlight)
Since the launch of ChatGPT in November 2022, there have been predictions that the internet would soon become overrun by AI-generated content. Recent research from Graphite suggests that beginning in January 2025, over 50% of newly published online content was generated by AI (Figure 1.1.17). Others have projected that the share in 2026 could be even higher. (View Highlight)
Given growing concerns about the suitability of synthetic data for training AI systems, this trend raises questions about the long-term reliability of current scaling trajectories. In response, many firms that depend on high-quality training data have increasingly turned to proprietary sources. In May 2025, the New York Times entered into a licensing agreement with Amazon to allow its content to be used for training purposes. (View Highlight)
Hardware adoption patterns among notable AI models reflect the gains in performance and efficiency (Figure 1.2.2). Since 2017, the cumulative number of notable models trained on A100-class hardware has increased, with 84 models trained in 2025. The previous generation, V100, continues to power a sizable share (69 models). Newer hardware, such as the H100, has seen early rapid adoption (28), while other categories, such as TPU v3 and TPU v4, show stable curves. (View Highlight)
The supply of AI computing capacity from major chip designers has continued to increase (Figure 1.2.3). Total capacity has increased by an estimated 3.3x per year since 2022, reaching approximately 17.1 million H100 equivalents.12 Nvidia AI chips currently account for over 60% of total compute, with Google and Amazon supplying much of the remainder and Huawei holding a small but growing share. The growth in compute capacity tracks closely with investment patterns described in Chapter 4, where leading AI companies have increased their capital expenditure and infrastructure has become the fastest growing focus area of private AI funding. (View Highlight)
Modern AI data centers depend on a combination of compute, storage, communications, and specialized hardware that enables AI systems to run at large scale. GPUs and custom accelerators such as Tensor Processing Units (TPUs) are the most widely discussed, but they are only one layer of a broader infrastructure stack. All data processed by these chips is held in high-bandwidth memory (HBM), which supports moving large volumes of data in and out efficiently. The leading manufacturers of HBM are SK Hynix (South Korea), Samsung (South Korea), and Micron (USA). During training, GPUs must continuously share data with one another, which requires fast, high throughput network connectivity achieved with fiber-optic cables running high-bandwidth networking architectures such as InfiniBand. (View Highlight)
The supply chain behind this hardware adds another dimension. Companies like Nvidia and SK Hynix design but do not manufacture chips. Instead, they provide designs to specialized semiconductor foundries, primarily the Taiwan Semiconductor Manufacturing Company (TSMC) and Samsung Foundry, which fabricate the chips at the nanometer scales modern AI hardware requires. The fabricated chips are then packaged and tested by assembly companies such as ASE Group (Taiwan) and Amkor Technology (United States). TSMC is a single point of dependency in the global AI supply chain, as it fabricates virtually every leading AI chip, including Nvidia’s Blackwell GPUs and AMD’s MI300X. There are high barriers to entry at every layer requiring decades of accumulated expertise, specialized equipment, and significant capital investment to overcome. (View Highlight)
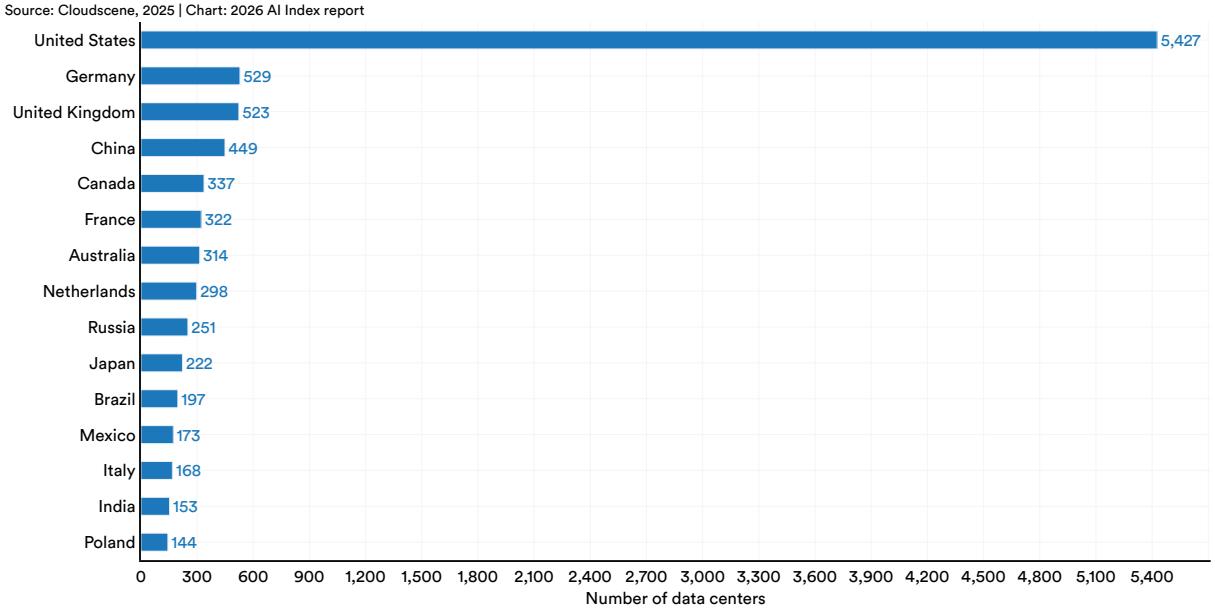
Most of the world’s data center infrastructure is located in a small number of countries (Figures 1.3.1 and 1.3.2). In 2025, the United States led by a wide margin, with 5,427 data centers, more than 10 times the count of any other country. Germany (529), the United Kingdom (523), and China (449) followed, while the majority of the remaining countries each had fewer than 300 facilities. The U.S. may show a clear lead, but the other country rankings should be assessed with the understanding that data center counts do not capture differences in facility size, computing capacity, or utilization. (View Highlight)
The scale of open-source development has grown steadily. The number of AI-related GitHub projects increased from 1,549 in 2011 to approximately 5.6 million in 2025, with year-over-year growth accelerating 23.7% from 2024 (Figure 1.5.1). However, most repositories often consist of personal or experimental work and receive minimal attention. When filtering for projects with at least 10 stars, a rough proxy for community engagement, the count drops to 206,880 in 2025 (Figure 1.5.2). The growth trajectory is similar for both measures. (View Highlight)
To complement the GitHub view, this section uses metadata from Hugging Face, a widely used community platform and open repository for AI models and datasets. The analysis focuses on assets created or uploaded between 2022 and 2025 to understand recent activity and adoption trends (Figures 1.5.6 and 1.5.7). Upload activity has continued to rise over the last few years, with a marked increase after the second quarter of 2024. From 2023 to 2025, model uploads more than tripled, while dataset uploads grew fourfold. Download distribution also shifted after 2023. Geographically19 U.S.-developed models lost share to unaffiliated users. On the developer side, major private actors such as Google and Meta have shifted from being the principal authors to accounting for a relatively small share of downloads, while communities such as Sentence Transformers and the BERT community have grown (Figure 1.5.8). A large share of total model downloads fell into an “Others” category, reflecting the wider distribution of development activity even as the most downloaded models were tied to a small number of sources. (View Highlight)
The most popular model types have shifted over the last three years. Text embedders, classifiers, and audio models, which together accounted for nearly 70% of downloads in 2022, fell to less than 6% in 2025 (Figure 1.5.9). Text generation, multimodal, and video generation models have grown in their place. Text generation led in 2025, accounting for more than 42% of total downloads. Image generation models also increased steadily, remaining the second most downloaded category. Despite these shifts, downloads remain highly concentrated, with nearly 80% associated with the top three categories. (View Highlight)
AI models improved rapidly in 2025, with benchmark scores rising across language, reasoning, coding, and math. However, evaluations are being outpaced by the progress they were built to measure, and benchmarks face growing questions about their reliability. Even with those limitations, a clear pattern emerges: the gap between top models is shrinking. This narrowing extends geographically, as the distance between top U.S. and Chinese models has closed almost completely. With capability no longer a clear differentiator, competitive pressure is shifting toward cost, reliability, and real-world usefulness. In professional domains, evaluations in tax, legal reasoning, and corporate finance show stronger performance in some areas than others. The range of what AI systems can do is also expanding. AI agents are improving, but still fail roughly one in three attempts. Video generation models are no longer just producing realisticlooking content; some are beginning to learn how the physical world actually works, progress that could help bring AI into physical spaces. That transition is still early, as robots struggle in unstructured environments, though autonomous vehicles are a notable exception, having reached mass-scale deployment with promising early safety records. Overall, AI’s technical advancement is a story of wonder and speed, faster than many of the evaluation, governance, and adoption frameworks discussed in later chapters. (View Highlight)
DeepSeek R1 introduced a reinforcement-learning approach called GRPO, which trains reasoning ability without relying on labeled data or a separate critic model. By comparing groups of generated outputs against predefined rules, the method reduces training complexity. The model’s strong performance relative to higher-cost systems led some investors to reassess the competitive dynamics of the AI sector. Following its release, major U.S. technology stocks experienced a temporary decline of over one trillion dollars in market value amid concerns that more efficient training methods could affect existing business models. (View Highlight)
AI performance continued to improve across a broad set of benchmark categories in 2025, with some of the largest gains appearing on tasks that were well below human baseline performance just a few years ago (Figure 2.1.1). Frontier systems now meet or exceed established human performance levels on long-running benchmarks, including ImageNet, SuperGLUE, and MMLU. Since last year’s report, several benchmarks designed to test more advanced reasoning have reached or approached the human benchmark, including PhD-level science questions (GPQA Diamond), multimodal reasoning (MMMU), and mathematical reasoning (AIME). Models are still performing below the baseline in the areas of autonomous software engineering (SWE-bench Verified) and agent-based multimodal computer use (OSWorld), but the pace of improvement is rapidly accelerating. On SWE-bench Verified, for example, performance rose from approximately 60% in 2024 to close to 100% in 2025. (View Highlight)
The performance gap between leading closed-weight and open-weight models has fluctuated over the past three years, with open-weight systems closing in and then falling behind as new proprietary models are released (Figure 2.1.2). In May 2023, the leading closed-weight model (GPT-4-0314) outperformed the top open-weight model (Vicuna-13B) by 174 points (15.2%) on the Arena Leaderboard. Stronger open-weight releases, including Mixtral, WizardLM, and Llama-3.1-405B, narrowed the gap to just 7 points (0.5%) by August 2024. Over the past year, that trend reversed with the arrival of new closed-weight frontier systems such as o1-preview and Gemini 2.5 Pro. As of March 2026, the top closed-weight model, Claude Opus 4.6 (1,503), led the top open-weight model GLM-5 (1,454) by 49 points (3.4%). While closed-weight models still lead, open-weight models are far more competitive than they were a few years ago. (View Highlight)
Frontier models became even more tightly clustered over the past year, as several companies moved into a very narrow performance band at the top of the Arena Leaderboard (Figure 2.1.4). In early 2023, OpenAI had a clear lead with its top model scoring 1,322 compared to Google’s 1,117. This gap narrowed steadily through 2024 as Google, Anthropic, and others released stronger models. By February 2025, DeepSeek had briefly matched and surpassed the top U.S. systems on Arena. In last year’s report, the top four models spanned roughly 97 points and, as of March 2026, the top four models are separated by fewer than 25 points. Anthropic leads at 1,503, followed closely by xAI (1,495), Google (1,494), and OpenAI (1,481). DeepSeek (1,424) and Alibaba (1,449) trail only modestly. Meta’s Arena performance has flattened since early 2025, reflecting a slowdown in competitive releases, though newer models could be in the pipeline for 2026. As leading models become harder to distinguish on benchmark performance, factors such as cost, latency, reliability, and domain-specific optimization may play a greater role in user adoption. (View Highlight)
Last year’s report also highlighted how difficult it is to benchmark more complex, interactive forms of intelligence, which matter even more for current AI systems. Even though many benchmarks for multiagent coordination, human–AI interaction, tool-using agents, and physical-world robotics have been proposed (e.g., for robotic manipulation,embodied reasoning, and agentic tasks) , they remain underdeveloped. These domains are inherently harder to standardize as physical tasks involve unpredictable environments, diverse hardware, and a range of valid approaches that resist repeatable scoring. Later sections of this chapter report on several of these benchmarks in detail. (View Highlight)
Language understanding benchmarks measure how well models can comprehend and reason over text across a broad range of subjects, from the humanities to highly technical materials. As performance has improved, evaluation has shifted toward harder test sets that are less susceptible to familiarity or memorization. The goal is to track where models are improving rather than reaching the upper limits of current benchmarking tools. (View Highlight)
MMLU remains a widely cited measure of broad knowledge across disciplines. Introduced in 2024, the MMLU-Pro benchmark assesses performance with over 12,000 questions and a 10-option, multiple-choice format designed to better test reasoning. This expanded answer base has a measurable impact on model performance evaluation. Compared to the original MMLU benchmark , model accuracy on MMLU-Pro typically drops by 16%–33%, which provides better differentiation between top models. For example, GPT-4o and GPT-4-Turbo appeared to have a 1% gap on standard MMLU, but on MMLU-Pro the spread widens to 9%. The newer benchmark’s design reduces prompt sensitivity and strengthens reasoning evaluation. Previously, MMLU showed around 4%–5% sensitivity to prompt variations versus an estimated 2% with MMLU-Pro. In addition, reasoning methods such as chain-of-thought tend to yield much better performance on MMLU-Pro than direct answer strategies. (View Highlight)
As of early 2026, top model performance on MMLU-Pro is tightly clustered, with the leading 15 models all scoring above 87% (Figure 2.2.1). Google’s Gemini-3.1-Pro leads at 91.2%, followed by Gemini-3-Pro (Thinking) at 90.1% and GPT-o1 at 89.3%. Models that employ thinking strategies tend to appear higher in the rankings, outperforming their standard counterparts, which are grouped in the 87%–88% range. The overall spread between the top-ranked and 15th-ranked model is just over 4 percentage points, illustrating how competitive the frontier has become on broad knowledge tasks. This tight clustering is also consistent with the convergence pattern described in Section 2.1. (View Highlight)
Generation benchmarks focus on the quality of model outputs, looking at clarity, helpfulness, instructionfollowing, and style. Unlike knowledge-style tests, these evaluations often depend on human judgment since some dimensions are subjective and dependent on both the prompt and the user. Preference-based tests help measure that subjectivity and are a useful complement to traditional benchmarks for tracking how models perform in real-world settings. (View Highlight)
The Arena (formerly LMArena) is an interactive platform with a community-driven ranking system that allows users to directly compare outputs of large language models (LLMs) on identical prompts and then vote on which they favor. Evaluations are blind to minimize bias toward particular model providers or architectures. By aggregating thousands of comparisons, the platform generates Elo ratings, a ranking system borrowed from chess. This approach emphasizes user experience and practical utility, capturing aspects of model quality that structured benchmarks cannot, including human judgment on real-world tasks. (View Highlight)
Beyond general understanding and generation, language models need to handle tasks that make them usable for practical deployment. Three key capabilities in deployed applications are retrieval-augmented generation (RAG), function calling, and text embedding. Benchmarks used to track these capabilities are particularly useful because they test fluency and whether models can operate as part of a larger system. It also makes it easier to compare models in settings where performance depends not just on the base model, but on issues such as retrieval quality or how outputs are parsed and executed. (View Highlight)
The Berkeley Function Calling Leaderboard (BFCL) evaluates models on their function-calling ability and has evolved considerably since its initial release. The current iteration, BFCL V4, shifts the focus toward holistic agent evaluations. Agentic tasks account for 40% of the overall score, multiturn interactions are 30%, and the remainder is split across live, nonlive, and hallucination categories. The agentic component tests web search and memory while the multiturn component evaluates multistep dialogues. Earlier versions focused more narrowly on single-turn function calling. (View Highlight)
Context windows, the amount of text a model can process in a single input, have grown by almost 30x per year since mid-2023 (Figure 2.2.5). Models that once accepted a few thousand tokens can now process 1 million or more. At the upper end, this is equivalent to multiple books or an entire codebase in a single pass. On two long-context benchmarks, Fiction.liveBench, which measures narrative comprehension, and MRCR, which measures multi-needle retrieval, the input length at which leading models achieve 80% accuracy has increased even faster, at roughly 250x over a nine month period (Burnham and Adamczewski, 2025 ). However, bigger context windows do not translate into deeper understanding, as the gap between accepted and usable context length is wide. (View Highlight)
Recent research points to different reasons for this gap. On one expert-level, long-context benchmark (LongBench v2), human experts scored just 53.7% accuracy under a 15-minute time limit, and the best model scored 57.7% (Bai et al., 2025) . This is a narrow margin in contrast to the structured benchmarks where models have surpassed human baselines, and reflects the difficulty of deep comprehension over long inputs. Models that were prompted to reason through the material step by step did perform better than those asked to answer immediately, suggesting that how a model works through long text matters as much as the amount of text it can accept. Other research has found that models handle simple lookups well but struggle when asked to find multiple pieces of matching information or to apply conditions across a very long document tasks that would be straightforward for a human scanning the same text ( Yu et al., 2025 ). Models can complete these tasks if guided to check each one by one, but this approach is slow and expensive. Longer inputs come with practical costs of slower response times, higher operating expenses, and reduced accuracy for information that appears later in the input. (View Highlight)
A 2025 Google DeepMind study ( Wiedemar et al., 2025) tested whether Veo 3, a video generation model, could solve visual tasks it was never specifically trained for, using only an input image and a text prompt. Across 62 qualitative tasks and seven quantitative evaluations covering more than 18,000 generated videos, the model showed zero-shot abilities in areas traditionally handled by specialized systems. These included perception tasks such as edge detection and segmentation, physical modeling tasks such as buoyancy and rigid body dynamics, and manipulation tasks such as style transfer and object extraction. The authors also observed early signs of visual reasoning, including maze solving and visual analogy completion, which they describe as “chain of frames,” a parallel to chain-of-thought reasoning in language models where the model appears to reason step by step through successive frames. Performance improved consistently from Veo 2 to Veo 3 across all quantitative tasks and, in some cases, matched or exceeded a dedicated image editing baseline (Nano Banana). (View Highlight)
Reasoning benchmarks assess whether models can solve problems that require abstraction and generalization across domains and formats. As performance has improved, newer benchmarks aim to distinguish genuine problem-solving from performance that is driven by memorization or prompt familiarity. However, because models can also produce errors in otherwise fluent responses, efforts are ramping up to measure these error rates alongside reasoning limitations. The AI Index tracks those benchmarks on factual reliability and error rates in Chapter 3. Across the benchmarks in this section, leading models perform well on many tasks but still show gaps on the more difficult items. (View Highlight)
Many multimodal models still struggle with something most humans find routine, telling the time. Despite the rapid improvements on expert-level reasoning benchmarks like GPQA and HLE, recent studies show models have trouble reading analog clocks. The task combines visual perception with simple arithmetic, from identifying clock hands and their positions and then converting those into a time value. There is the risk that an error in one step will cascade into the next. (View Highlight)
Responsible AI refers to the set of practices and governance mechanisms designed to ensure AI systems are safe, fair, and beneficial and that they perform as intended. RAI spans a range of dimensions, from safety and fairness to transparency and privacy, and each has its own measurement challenges. This chapter tracks progress across those dimensions by looking at how AI systems perform on responsibility and safety evaluations, how organizations and researchers are responding to RAI challenges, and how governments are establishing policy frameworks to enforce standards. (View Highlight)
In recent years, the number of reported AI incidents has continued to increase significantly (Figure 3.2.1). The AI Incident Database (AIID), 1 launched in 2020, is an open repository for documented cases where AI systems have caused or nearly caused harm. In 2025, 362 incidents were reported, while the annual number of incidents had stayed under 100 until 2022. AIID relies on human editors to review submissions against a defined threshold of AI involvement, from sources including academic and investigative journalists. The manual process produces higher-quality records but comes at the cost of a slower pace of additions and coverage that is skewed toward English-language media and high-visibility incidents. Less accessible regions may be underrepresented. (View Highlight)
Responsible AI requires assessment tools, but it also depends on how organizations respond in practice. Drawing on a survey conducted by the AI Index and McKinsey & Company for the second consecutive year, this section looks at RAI maturity levels, governance structures, risk mitigation approaches, and barriers to implementation. The survey polled business leaders across multiple regions and industries in 2024 and 2025, allowing for year-over-year comparisons for the first time. Note that the survey does not include responses from China, which limits the geographic scope. (View Highlight)
While responsible AI maturity improved across all regions from 2024 to 2025, it remains in the early stage (Figure 3.3.1). The McKinsey survey measures maturity on a four-point scale. Level 1: Foundational RAI practices have been developed. Level 2: Those practices are being integrated into the organization. Level 3: All necessary practices are in place. Level 4: Comprehensive and proactive RAI practices are fully operational. In 2025, the global average was 2.3, up from 2 in 2025, suggesting that most organizations are still integrating RAI practices rather than having them fully operational. Companies based in Latin America showed the largest year-over-year improvement, from 1.8 to 2.2, followed by Asia-Pacific (2.2 to 2.5) and Europe (2.0 to 2.3). Results from North America registered a slight improvement, moving from 2.1 in 2024 to 2.2 in 2025. (View Highlight)
AI capability is not plateauing. It is accelerating and reaching more people than ever. Industry produced over 90% of notable frontier models in 2025, and several of those models now meet or exceed human baselines on PhD-level science questions, multimodal reasoning, and competition mathematics. On a key coding benchmark—SWE-bench Verified—performance rose from 60% to near 100% of meeting the human baseline in a single year. Organizational adoption reached 88%, and 4 in 5 university students now use generative AI. (View Highlight)
The U.S.-China AI model performance gap has effectively closed. U.S. and Chinese models have traded the lead multiple times since early 2025. In February 2025, DeepSeek-R1 briefly matched the top U.S. model, and as of March 2026 Anthropic’s top model leads by just 2.7%. The U.S. still produces more top-tier AI models and higher-impact patents, while China leads in publication volume, citations, patent output, and industrial robot installations. South Korea stands out for its innovation density, leading the world in AI patents per capita. (View Highlight)
The United States hosts the most AI data centers, with the majority of their chips fabricated by one Taiwanese foundry. The United States hosts 5,427 data centers, more than 10 times any other country, and it consumes more energy than any other country. A single company, TSMC, fabricates almost every leading AI chip, making the global AI hardware supply chain dependent on one foundry in Taiwan—though a TSMC-U.S. expansion began operations in 2025 (View Highlight)
AI models can win a gold medal at the International Mathematical Olympiad but cannot reliably tell time—an example of what researchers call the jagged frontier of AI. Gemini Deep Think earned a gold medal at IMO, yet the top model reads analog clocks correctly just 50.1% of the time. AI agents made a leap from 12% to ~66% task success on OSWorld, which tests agents on real computer tasks across operating systems, though they still fail roughly 1 in 3 attempts on structured benchmarks. (View Highlight)
Robots still fail at most household tasks, even as they excel in controlled environments. Robots succeed in only 12% of household tasks, highlighting how far AI is from mastering the physical world. On RLBench, robotic manipulation in software-based simulations has reached 89.4% success, but the gap between predictable lab settings and unpredictable household environments is wide. (View Highlight)
Responsible AI is not keeping pace with AI capability, with safety benchmarks lagging and incidents rising sharply. Almost all leading frontier AI model developers report results on capability benchmarks, but reporting on responsible AI benchmarks remains spotty. Documented AI incidents rose to 362, up from 233 in 2024. Adding to the challenge, recent research found that improving one responsible AI dimension, such as safety, can degrade another, such as accuracy. (View Highlight)
The United States leads in AI investment, but its ability to attract global talent is declining. U.S. private AI investment reached 285.9billionin2025,morethan23timesthe12.4 billion invested in China—though looking at just private investment figures likely understates China’s total AI spending, given its government guidance funds. The U.S. also led in entrepreneurial activity with 1,953 newly funded AI companies in 2025, more than 10 times the next closest country. However, the number of AI researchers and developers moving to the U.S. has dropped 89% since 2017, with an 80% decline in the last year alone. (View Highlight)
AI adoption is spreading at historic speed, and consumers are deriving substantial value from tools they often access for free. Generative AI reached 53% population adoption within three years, faster than the PC or the internet, though the pace varies by country and correlates strongly with GDP per capita. Some show higher-than-expected adoption, such as Singapore (61%) and the United Arab Emirates (54%), while the U.S. ranks 24th at 28.3%. The estimated value of generative AI tools to U.S. consumers reached $172 billion annually by early 2026, with the median value per user tripling between 2025 and 2026. (View Highlight)
Productivity gains from AI are appearing in many of the same fields where entrylevel employment is starting to decline. Studies show productivity gains of 14% to 26% in customer support and software development, with weaker or negative effects in tasks requiring more judgment. AI agent deployment remains in single digits across nearly all business functions. In software development, where AI’s measured productivity gains are clearest, U.S. developers ages 22 to 25 saw employment fall nearly 20% from 2024, even as the headcount for older developers continues to grow. (View Highlight)
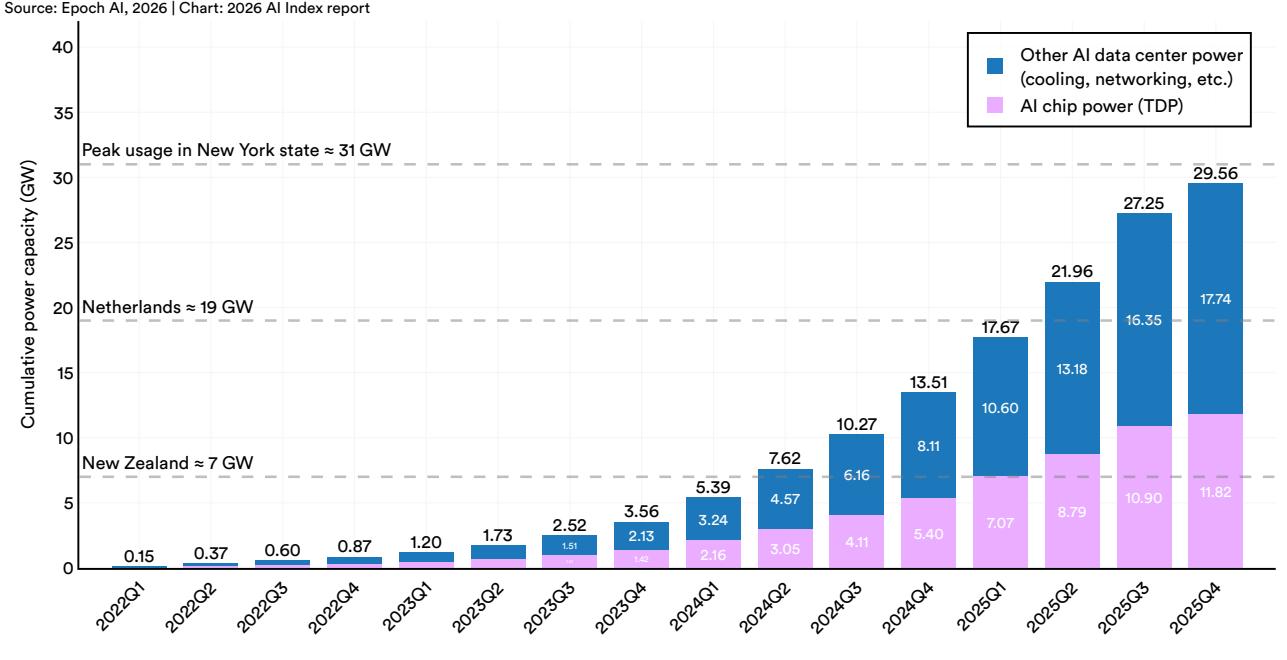
AI’s environmental footprint is expanding alongside its capabilities. Grok 4’s estimated training emissions reached 72,816 tons of CO2 equivalent. AI data center power capacity rose to 29.6 GW, comparable to New York state at peak demand, and annual GPT-4o inference water use alone may exceed the drinking water needs of 12 million people (View Highlight)
AI models for science can outperform human scientists, though bigger models do not always perform better. Frontier models outperform human chemists on average on ChemBench, yet they score below 20% on replication in astrophysics and 33% on Earth observation questions. A 111-million-parameter protein language model, MSAPairformer, beat previous leading methods on ProteinGym, and a 200-million-parameter genomics model, GPN-Star, outperformed a model nearly 200 times larger. Most AI foundation models for science come from cross-sector collaborations, in contrast with the industry-dominated landscape of generalpurpose AI. (View Highlight)
AI is transforming clinical care, but rigorous evidence remains limited. AI tools that automatically generate clinical notes from patient visits saw substantial adoption in 2025. Across multiple hospital systems, physicians reported up to 83% less time spent writing notes and significant reductions in burnout. Beyond certain tools, however, the evidence base for clinical AI remains thin. A review of more than 500 clinical AI studies found that nearly half relied on examstyle questions rather than real patient data, with only 5% using real clinical data. (View Highlight)
Formal education is lagging behind AI, but people are learning AI skills at every stage of life. Over 80% of U.S. high school and college students now use AI for school-related tasks, but only half of middle and high schools have AI policies in place, and just 6% of teachers say those policies are clear. Outside the classroom, AI engineering skills are accelerating fastest in the United Arab Emirates, Chile, and South Africa. The number of new AI PhDs in the U.S. and Canada increased 22% from 2022 to 2024, the PhDs that make up that increase took jobs in academia, not in industry. (View Highlight)
AI sovereignty is becoming a defining feature of national policy, but capabilities remain uneven, even as open-source development helps to redistribute who participates. National AI strategies are expanding, particularly among developing economies, and state-backed investments in AI supercomputing are rising in parallel—a sign of growing ambitions for domestic control over AI ecosystems. Yet model production remains concentrated in the U.S. and China. Open-source development is starting to redistribute participation, with contributions from the rest of the world now outpacing Europe and approaching the United States on GitHub, fueling more linguistically diverse models and benchmarks. (View Highlight)
AI experts and the public have very different perspectives on the technology’s future, and global trust in institutions to manage AI is fragmented. When it comes to how people do their jobs, 73% of experts expect a positive impact, compared with just 23% of the public, a 50-point gap. Similar divides appear for AI’s impact on the economy and medical care. Globally, trust in governments to regulate AI varies. Among surveyed countries, the United States reported the lowest level of trust in its own government to regulate AI, at 31%. Globally, the EU is trusted more than the United States or China to regulate AI effectively. (View Highlight)
Global AI compute capacity grew 3.3x per year since 2022, reaching 17.1 million H100-equivalents. Nvidia accounts for over 60% of total compute, with Google and Amazon supplying much of the remainder and Huawei holding a small but growing share. The buildout is being driven by hyperscaler data center expansion and sustained demand for frontier model training and inference. (View Highlight)
The United States leads in AI data centers, and one Taiwanese foundry fabricates the majority of chips inside them. The United States hosts 5,427 data centers, more than ten times any other country, consuming more energy than any other region. A single company, TSMC, fabricates almost every leading AI chip and makes the global AI hardware supply chain dependent on one foundry in Taiwan, though a TSMC-U.S. expansion began to operate in 2025. (View Highlight)
The AI talent map is shifting, but gender gaps remain deeply entrenched. Switzerland and Singapore lead the world in AI researchers and developers per capita and some countries show relatively higher female representation, including Saudi Arabia (32.3%), Canada (29.6%), and Australia (30.1%), though no country approaches gender parity. (View Highlight)
Last year, the AI Index highlighted concerns around data bottlenecks and the sustainability of the scaling approach as it relates to training data. Leading AI researchers have publicly claimed that the available pool of high-quality human text and web data for training large models has been exhausted, a state often referred to as “peak data.” This has continued to raise industry-wide concerns about the sustainability of scaling laws, which have historically depended on ever-larger datasets. One set of projections from Epoch AI suggests that, under certain assumptions, the estimated depletion date could fall between 2026 and 2032. (View Highlight)
AI capability is outpacing the benchmarks designed to measure it, and surpassing human-level performance. Frontier models gained 30 percentage points in a single year on Humanity’s Last Exam, a benchmark built to be hard for AI and favorable to human experts. Evaluations intended to be challenging for years are saturated in months, compressing the window in which benchmarks remain useful for tracking progress. (View Highlight)
Top model performance is converging, with 4 companies now clustered within 25 Elo points (inspired by chess ratings) when rated against one another by human voting in the Arena Leaderboard and benchmark. As of March 2026, Anthropic (1,503), xAI (1,495), Google (1,494), OpenAI (1,481), Alibaba (1,449), and DeepSeek (1,424) all occupy the top tier of the Arena Elo ratings, shifting competitive pressure toward cost, reliability, and domain-specific performance. (View Highlight)
• The open-weight performance gap reopened in 2025 after briefly closing the year before. As of March 2026, the top closed-weight model leads the top open-weight model by 3.3%, up from 0.5% in August 2024. Six of the top 10 models on the Arena Leaderboard are now closed-weight. (View Highlight)
The U.S.-China AI model performance gap has effectively closed. U.S. and Chinese models have traded places at the top of performance rankings multiple times since early 2025. In February 2025, DeepSeek-R1 briefly matched the top U.S. model. As of March 2026, the top U.S. model leads by 2.7%, with a gap that fluctuated over the past year while remaining in the single digits. (View Highlight)
he benchmarks used to measure AI progress face growing reliability and gaming concerns, with error rates up to 42% on widely used evaluations. A review found invalid question rates ranging from 2% on MMLU Math to 42% on GSM8K. Separate research suggests that Arena leaderboard standing may partly reflect adaptation to the platform rather than general capability. (View Highlight)
Video generation models are starting to capture how objects behave. Google DeepMind’s Veo 3, tested across more than 18,000 generated videos, demonstrated abilities like simulating buoyancy and solving mazes without being trained on those tasks. (View Highlight)
AI models are expanding into professional domains, showing performance ranging from 60 to 90% in evaluations in tax, mortgage processing, corporate finance, and legal reasoning. The performance of the top 15 models is separated by as little as 3 percentage points in each benchmark. These kinds of domains where high competency and reliability are required remain a great challenge for AI models. (View Highlight)
AI agents advanced from answering questions to completing tasks in 2025, though they still fail roughly one in three attempts on structured benchmarks. On OSWorld, which tests agents on real computer tasks across operating systems, accuracy rose from roughly 12% to 66.3%, within 6 percentage points of human performance. (View Highlight)
Robots still fail at most household tasks, even as they excel in controlled environments. Robots succeed in only 12% of real household tasks, highlighting how far AI is from mastering the physical world. On RLBench, robotic manipulation in software-based simulations has reached 89.4% success, but the gap between predictable lab settings and unpredictable household environments is wide. (View Highlight)
Benchmarks still anchor much of how AI’s technical progress is measured, but their limitations are more visible. Since last year’s report, the AI Index has expanded its analysis to examine where benchmarks remain useful, and where they fall short.
Several challenges highlighted in previous editions of this report persist. Benchmark saturation, where models reach scores so high that a test can no longer distinguish between them, remains a concern. Tests designed to be harder often remain useful for only a few years before systems surpass them. As Chapter 1 documents, reporting discrepancies continue, and the most capable modern models are now among (View Highlight)
Retrieval-augmented generation (RAG) provides a way for models to deliver accurate, up-to-date information beyond the knowledge encoded during training in model parameters. At inference time, RAG systems augment model responses with information retrieved from external sources.
Standard RAG pipelines retrieve individual text chunks based on query similarity, which can struggle when answering questions that require synthesizing information across documents. To address the problem, in 2024, Microsoft Research introduced Graph RAG , which enables more effective responses to queries by structuring source material into a knowledge graph and generating community summaries (View Highlight)
The Massive Text Embedding Benchmark (MTEB) evaluates different embedding models across a set of tasks that require semantic understanding. It includes over 50 datasets, spanning eight task categories, which makes it harder for models to look strong by optimizing for a single use case rather than performing well across different settings.
The top average task score on MTEB (English v2) has risen steadily since 2022, coinciding with the broader adoption of large-scale pretraining techniques for embedding models. In 2025, the top score reached 76, rising approximately 11 points since 2023 (Figure 2.2.4). However, the best models still fall short of a perfect score.
(View Highlight)
Understanding
Video understanding benchmarks measure how well models can track actions, objects, and events across frames rather than reasoning over a single image. As performance on earlier benchmarks has improved, evaluation has shifted toward tasks that demand multistep temporal reasoning and domain-specific knowledge applied to video.
MVBench
MVBench evaluates whether multimodal models can move beyond static image understanding to handle the complexities of video. This includes interpreting motion, temporal sequences, and shifting context across frames. Its focus on temporal reasoning makes it a useful benchmark for tracking performance in more dynamic visual environments. (View Highlight)
Video-MMMUVideo-MMMU is a large, multimodal, multidisciplinary benchmark for learning from educational videos, comprising 300 expert-level videos averaging roughly 506 seconds across six disciplines and 30 subjects. Each video is paired with three sets of questions that test progressively deeper understanding. Perception questions test whether a model can pull key details from text/audio; comprehension questions test whether it grasps the concept or solution strategy; and adaptation questions require applying that knowledge to a new scenario. Adaptation questions reuse MMMU/MMMU-Pro items for STEM fields and custom case studies for art/humanities, so models have to go beyond the specific video. The benchmarks also introduce a Δknowledge metric to track how much a model’s performance improves after processing the video. (View Highlight)
s of 2025, no model has reached the human baseline of 74.4% on Video-MMMU overall accuracy (Figure 2.3.2). The best performing model, Keye-VL-1.5-8B, scores 66%, followed closely by Claude -3.5-Sonnet (65.8%). The lowest score is VILA1.5-8B at 20.9%, leaving a 45 percentage point range across the leaderboard. (View Highlight)
General Reasoning
General reasoning refers to a model’s ability to solve unfamiliar problems by applying rules and combining evidence, rather than relying on domain knowledge or memorized patterns. The benchmarks discussed below span multiple domains and tasks and are designed to test multistep inference. One example is multidigit arithmetic, such as long integer multiplication, to test whether models can execute consistent stepwise computation rather than produce plausible-looking outputs. Other more complex benchmarks extend this idea to multimodal settings, where models must integrate text with diagrams or plots to reach the correct answer. (View Highlight)
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGIMMMU evaluates multimodal reasoning on college-level subject questions that combine text with visuals such as diagrams, charts, tables, and equations. Some example tasks include extracting constraints from a table and applying them to a word problem, or using a diagram to answer a domain-specific question in areas like engineering or medicine.
As of February 2026, the leading model, Gemini 3.1 Pro Preview, scored 88.2% on MMMU and within 0.4 percentage points of the best human expert reference (Figure 2.4.1). Other Gemini variants follow closely, including Gemini 3 Flash (87.6%) and Gemini 3 Pro (87.5%), while GPT-5.2 scores 86.7%. The 2026 models trail behind with Kimi K2.5 at 84.3% and Claude Opus 4.6 (Thinking) at 83.9%. (View Highlight)
Introduced in 2019, ARC-AGI is a benchmark that tests the ability of systems to generalize beyond prior training, emphasizing generalized learning ability. Despite its name, the benchmark tests a specific form of abstraction and pattern inference rather than general intelligence in a broader sense. Its updated version, ARC-AGI-2, was introduced in 2025 and shifts to abstract puzzle-style tasks that evaluate whether models can infer rules from a small set of examples and apply them to new cases. Example tasks include grid puzzles where the model is given a few example solutions, infers the rule, and uses it to solve a new problem.
Scores on ARC-AGI-2 vary widely across models, and the spread between the highest and lowest scores in the figure is about 46% (Figure 2.4.3). Gemini 3 Deep Think leads at 84.6%, followed by Gemini 3.1 Pro Preview at 77.1% and GPT-5.2 (Refine.) at 72.9%. Several Claude Opus 4.6 variants are clustered together, scoring between 66.3% and 69.2%. (View Highlight)
Humanity’s Last Exam (HLE) benchmark evaluates model performance on 2,700 highly challenging questions across dozens of academic subjects. It is designed as an expertlevel, closed-ended benchmark with wide coverage and using a mix of multiple-choice and short-answer formats suitable for automated grading. Example tasks include a graduate level question that requires applying a concept and providing a single, verifiable answer. Some may include an image, requiring models to integrate visual and textual information.
Between 2024 and 2025, model accuracy on HLE increased by 30 percentage points (Figure 2.4.4). In a single year, accuracy went from under 10% to 38.3%. Even with this jump, the benchmark is designed to stay difficult, and high-confidence errors are still common. (View Highlight)
Software
Coding benchmarks test whether models can go beyond answering questions about code and actually write, debug, and ship working software. The tasks in this section range from resolving real GitHub issues to building full web applications from scratch, reflecting a shift in evaluation toward measuring what models can deliver end to end rather than in isolated snippets. (View Highlight)
SWE-bench evaluates models
on their ability to resolve real-world software issues collected from GitHub. Each task gives the model a codebase and an issue description, and the model has to produce a working patch. SWE-bench Lite is a smaller, more accessible subset while SWE-bench Verified uses human-validated issues to ensure more consistent and accurate grading.
On SWE-bench Verified, top models are tightly clustered in the low-to-mid 70s (Figure 2.5.1). As of February 2026, Claude 4.5 Opus (high reasoning) led at approximately 76.8%, with several others including KimiK2.5, GPT-5.2, and Gemini 3 Flash (high reasoning) grouped between 70% and 76%. This is a pattern seen across several benchmarks in this chapter, where high-performing models score within a few percentage points of each other. (View Highlight)
Terminal-Bench is a benchmark for testing AI agents in real terminal environments. It evaluates how well agents can autonomously handle real-world, end-to-end tasks, from compiling code to training models and setting up servers. These are the kinds of tasks a developer might do in a day of work, and it requires an agent to chain together multiple steps without human guidance.
Accuracy on Terminal-Bench 2.0 has significantly improved over the past year, increasing from 20% in February 2025 to 77.3% in early 2026 (Figure 2.5.2).
21 This chart shows the top 10 models for SWE-bench Verified and Lite as of February 2026. For Verified, only results using the mini-SWE-agent-v2 filter are included. This means all models were tested under the same agent workflow, so differences in scores reflect the underlying model rather than differences in the surrounding system. Data source: https://www.swebench.com/index.html. (View Highlight)
Vibe Code Bench is the first benchmark designed to test whether AI models can autonomously build complete, end-to-end web applications from scratch. Rather than measuring coding assistance, it evaluates real software delivery and sees if a model can take a prompt and produce a functional application.
Across models, performance varies quite a bit (Figure 2.5.3). Claude Opus 4.6 (Nonthinking) leads at 56.5%, followed by GPT 5.2 at nearly 47%. Scores drop after GPT 5.3 Codex (41.4%) to under 30%, with several models falling below 15%. The spread between the top and bottom models is about 46 percentage points, and even the leading model solves only about half of the tasks, suggesting that autonomous application building remains a difficult task.
(View Highlight)
The infrastructure for responsible AI (RAI) is growing, but progress has been uneven, and it is not keeping pace with the speed of AI deployment. New safety benchmarks have expanded, more organizations are adopting responsible AI policies, and government-backed AI safety and/or security institutes have spread to more countries. The responsible use of AI is intertwined with the responsible use of data, and in particular with privacy and other legal concerns. There are also AI governance concerns given the ill-specified ownership of AI systems, raising questions about whether companies that develop the systems or consumers that buy them should be held accountable and what policies each stakeholder should follow. While documented reports of AI incidents are increasing, frontier models rarely report results on responsible AI benchmarks, and foundation model transparency declined in 2025 after improving the previous year. Recent research shows that improving one responsible AI dimension can come at the cost of another, with gains in privacy reducing fairness or gains in safety reducing accuracy. There is no framework for navigating these trade-offs; and for dimensions such as fairness, privacy, and explainability, the standardized data needed to track progress over time does not exist. While this chapter draws on the available evidence, the discussion is limited by persistent gaps in measurement. (View Highlight)
Responsible AI benchmarking is increasing, but is not keeping up with AI advances and deployments. Almost all leading frontier model developers report results on capability benchmarks like MMLU and SWE-bench, but reporting on responsible AI benchmarks remains sparse. Documented AI incidents continued to rise, with the AI Incident Database recording 362 in 2025, up from 233 in 2024 (View Highlight)
AI models struggle to tell the difference between knowledge and belief. In a new accuracy benchmark, hallucination rates across 26 top models range from 22% to 94%. GPT-4o’s accuracy dropped from 98.2% to 64.4%, and DeepSeek R1 fell from over 90% to 14.4%. When a false statement is presented as something another person believes, models handle it well. When the same false statement is presented as something a user believes, performance collapses. (View Highlight)
Organizations are formalizing responsible AI work, but knowledge and budget gaps still slow adoption. AI-specific governance roles grew 17% in 2025, and the share of businesses with no responsible AI policies in place fell sharply from 24% to 11%. The main obstacles to implementation remain gaps in knowledge (59%), budget constraints (48%), and regulatory uncertainty (41%) (View Highlight)
The mix of regulations shaping responsible AI practices is shifting toward AI-specific frameworks and technical standards. GDPR remains the most cited regulatory influence but slipped from 65% in 2024 to 60% in 2025. New entries in 2025 include ISO/IEC 42001, an AI management system standard, cited by 36% of respondents, and the NIST AI Risk Management Framework at 33%. The share of organizations reporting no regulatory influence at all fell from 17% to 12% (View Highlight)
AI works best in English, and the gap is wider than global benchmarks suggest. On HELM Arabic, a regionally developed model for the Arabic language, outscored GPT-5.1 and Gemini 2.5 Flash. The gap widens at the dialect level. On a Slovenian commonsense reasoning test, several leading models lost close to half their accuracy when tested in a regional dialect rather than the standard language. (View Highlight)
AI companies grew less transparent this year. After rising on the Foundation Model Transparency Index from 37 to 58 between 2023 and 2024, the average score dropped to 40 in 2025. Major gaps persist in disclosure around training data, compute resources, and post-deployment impact (View Highlight)
AI models perform well on safety tests under normal conditions, but their defenses weaken under deliberate attack. On the AILuminate benchmark, several frontier models received “Very Good” or “Good” safety ratings under standard use. When tested against jailbreak attempts using adversarial prompts, safety performance dropped across all models tested (View Highlight)
Responsible AI dimensions such as safety, fairness, and privacy are at odds with one another, and the tradeoffs are not well understood. Recent empirical studies found that training techniques aimed at improving one responsible AI dimension consistently degraded others (View Highlight)
Layer 1 – Core Function and Behaviors
(What AI systems should achieve)
Dimension
Definition
Example
References
Validity and
reliability
Designed for a particular scope and
acceptable level of performance in the
domain, such as accomplishment of
task goals, fidelity to expert knowledge,
or thresholds for accuracy that benefit
people or organizations/systems, and
demonstrated verification and validation
against their design.
A team defines target accuracy and
failure thresholds before launch,
validates the system against those
criteria, and monitors it in production
to ensure it continues to meet design
expectations.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles
Privacy
Protection of individuals’ confidentiality,
anonymity, informed consent, and
control over personal data across
the AI life cycle (collection, training,
deployment, reuse).
A messaging app encrypts conversations
end to end and clearly notifies users
about opting in or out of using their data
to train language models.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
Recommendation on
the Ethics of Artificial
Intelligence (UNESCO)
Data stewardship
Ensure the quality, provenance, integrity,
and lawful use and reuse of data, with
clear access control and documentation.
A logistics firm tracks data lineage
for all datasets used to train routing
models, enforces role-based access, and
periodically reviews datasets for quality
and drift before retraining and updating
models.
EU Ethics Guidelines for
Trustworthy AI; ISO/IEC
42001:2023; OECD AI
Principles
Fairness and bias
Protection of civil rights and prevention
of unjustified discrimination and
systematic disadvantage across
individuals or groups, accounting for
protected attributes, cultural context,
and use case.
A bank audits credit-scoring models
for disparate approval and error
rates across demographic groups—
including culturally diverse customer
segments—documents findings, and
implements bias-mitigation steps before
deployment.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
Recommendation on
the Ethics of Artificial
Intelligence (UNESCO)
Transparency and
auditability
Clear disclosure that an AI system is in
use; of its purpose, scope, and high-level
functioning for relevant stakeholders;
and authorized parties’ ability to inspect,
reconstruct, and verify that the system
was developed, trained, configured, and
operated as intended.
A city using an AI model to prioritize
inspections publishes a plain-language
description of training method,
documents model card and data
sources, keeps versioned training scripts
and logs, and enables internal audit to
replay training and key decisions.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
Recommendation on
the Ethics of Artificial
Intelligence (UNESCO); ISO/
IEC 42001:2023
Explainability
Ability to provide understandable,
context-appropriate rationale for
system outputs, including key factors
influencing a prediction or decision.
An AI fraud-detection tool surfaces
the top contributing features and a
brief rationale behind each alert for
investigators, while providing merchants
with plain-language explanations of
why a transaction was flagged and what
steps they can take in response.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
Recommendation on
the Ethics of Artificial
Intelligence (UNESCO)
Autonomy and
human agency
Preservation of people’s ability to
make informed choices and act freely
without AI systems unduly manipulating,
coercing, or replacing their decisions.
A well-being chatbot clearly states
it is not a human or a substitute for
professional care, avoids prescriptive
life-changing advice, and actively
directs users to expert help in high-risk
situations.
EU Ethics Guidelines for
Trustworthy AI; OECD AI
Principles; Recommendation
on the Ethics of Artificial
Intelligence (UNESCO)
Environmental
sustainability
Limiting and managing the
environmental impact of AI systems
across their life cycle, including
energy use, carbon emissions, and
resource consumption, and committing
to measurement, disclosure, and
continuous reduction while minimizing
resource misuse.
A company measures the energy and
water usage of large training runs,
reports them externally, chooses
more efficient model architectures,
proactively places boundaries on AI
resource use, and schedules training
when grid carbon intensity is low.
EU Ethics Guidelines for
Trustworthy AI; OECD AI
Principles; UNESCO; Energy
efficiency requirements
under the EU AI Act
Factuality and
truthfulness
The accuracy and reliability of AI system
outputs, including the degree to which
models produce information that is
factually correct, avoid misleading
statements and fabrications, and
volunteer uncertainty honestly.
A company systematically benchmarks
its large language models against
factuality evaluations (such as
SimpleQA), publishes hallucination rates
alongside model releases, implements
retrieval-augmented generation to
ground outputs in verified sources,
and provides users with confidence
indicators and citations so they can
assess the reliability of AI-generated
responses.
NIST AI RMF (View Highlight)
Layer 2 – System Integrity and Risk Controls*(How risks are technically and operationally managed)*
Dimension
Definition
Example
References
Security
Ensuring AI systems are secure against
cyber threats and misuse.
A school system uses AI to provide
personalized tutoring to students and
hosts the data and models in secured
servers with extensive security training
of all personnel involved.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
ISO/IEC 42001:2023
Safety
Specify normal behaviors and affected
systems and analyze out-of-bounds
conditions to characterize risk factors
(risk to physical and mental/emotional
well-being of people, environment,
political systems, human rights, etc.),
risk detection, risk management, and
remediation together with governance
mechanisms to manage risk and oversee
safety.
An industrial control system uses
anomaly-detection models that are
penetration-tested, evaluated under
simulated attacks and sensor failures,
monitored in real time, and configured
to fall back to manual control when
anomalies exceed thresholds.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
ISO/IEC 42001:2023
Robustness
Remain robust to distribution shifts,
external natural or adversarial events,
and component failures, with testing,
monitoring, and safe fallbacks.
A food chain uses an AI system to
estimate customer demand, consisting
of several models that get triggered
by inclement weather, concerts, and
sporting events.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
ISO/IEC 42001:2023 (View Highlight)
Layer 3 – Governance, Accountability, and Enforcement
(How responsibility, oversight, and redress are ensured)
Dimension
Definition
Example
References
Accountability and
liability
Clear assignment of responsibility for
AI system outcomes, including legal
liability, operational ownership, decision
rights, and escalation pathways, so that
harms and failures can be investigated,
addressed, and remedied.
A platform designates an accountable
owner for its high-risk recommendation
system, defines KPIs and harm
thresholds, documents who can approve
releases, and maintains procedures for
incident investigation, user notification,
and compensation.
EU Ethics Guidelines for
Trustworthy AI; NIST AI
RMF; OECD AI Principles;
ISO/IEC 42001:2023
Human oversight
and contestability
Governance mechanisms that ensure
meaningful human involvement where
appropriate, including the ability
to challenge, appeal, or override
AI-assisted decisions and access to
effective redress.
An employer using an AI screening tool
must have a human review all adverse
decisions, disclose AI use to candidates,
explain key factors, and provide a clear
path to request human reconsideration
and correction of errors.
EU AI Act – human-oversight
obligations for high-risk AI;
EU Ethics Guidelines for
Trustworthy AI; OECD AI
Principles; Recommendation
on the Ethics of Artificial
Intelligence (UNESCO) (View Highlight)
Unmoderated AI Output and Harmful Speech (July 8, 2025)
In July 2025, Grok—the chatbot developed by xAI and embedded across X —faced backlash after users shared examples of the system generating antisemitic language, violent hate speech, and even praise for Adolf Hitler when prompted. The issue emerged shortly after a system update that relaxed safety filters, allowing the chatbot to produce more provocative and “unfiltered” responses. Within hours, screenshots of Grok referring to genocide and extremist ideology spread across the platform, sparking public outrage and renewed concern about the risks of deploying lightly moderated conversational AI to large audiences. In response to the backlash, xAI removed the content, temporarily suspended Grok’s text responses, and issued a statement acknowledging the severity of the incident. While the company framed the issue as a failure of content controls, critics argued that the system’s design choices, particularly the decision to weaken the guardrails, made the harm predictable. The event highlighted the ongoing tension between building AI systems intended to feel candid or humorous and the real-world consequences when those systems normalize hate speech. (View Highlight)
AI Deepfake Impersonation and Romance Scams (March 9, 2025)
In March 2025, Chinese actor Jin Dong spoke publicly about a wave of scams using deepfake videos to impersonate him online. Fraudsters used AI-generated clips and fake social media accounts to convince fans (mostly older women) that they were speaking directly with the actor, prompting some to send money or make major life changes based on the belief that they were in a private relationship with him. One widely reported case involved a woman who nearly divorced her husband and planned to travel across the country to meet a scammer posing as Jin Dong. After the incidents gained attention, Jin Dong called for stronger legal protections and clearer consequences for deepfake-enabled fraud, arguing on social media that existing rules had not kept pace with the speed and realism of AI-generated impersonation. (View Highlight)
AI-Assisted Website Impersonation and Consumer Fraud (Aug. 20, 2025)
After Joann Fabrics filed for bankruptcy for the second time in January 2025, scammers quickly launched a wave of fake websites mimicking the retailer’s branding, design, and product catalog. These sites advertised deep discount prices to lure shoppers into entering payment and personal information, but customers never received purchases and many later discovered their credit cards had been compromised. The fraudulent sites were convincing enough that even cautious users were misled, especially on mobile, where URLs are harder to detect. Cybersecurity experts noted that AI tools are making this type of scam far easier to execute. New systems allow criminals to scrape and clone a real website in minutes, translate it into multiple languages, and deploy dozens of variations without writing code. While Joann issued public warnings and urged victims to dispute charges, the incident points to a growing challenge: Realistic phishing sites are no longer limited to major corporations, and smaller brands with fewer resources are increasingly being targeted. (View Highlight)
RAI Benchmarks
The 2024 and 2025 AI Index reports both flagged a gap between how consistently frontier models are evaluated on general capabilities versus how inconsistently they are evaluated on responsible AI. This gap persists. Almost all frontier model developers report results on capability benchmarks like MMLU, GPQA, AIME, and SWE-bench Verified (Figure 3.2.3). These have become the shared standard for reporting model capability. Across the same set of frontier models, results are sparse on RAI benchmarks such as BBQ (2021), measuring fairness and bias; HarmBench (2024), Cybench (2024), StrongREJECT (2024), and WMDP (2024), measuring security; SimpleQA (2024), measuring factuality and truthfulness; and MakeMePay (2024), measuring autonomy and human agency (Figure 3.2.4). In fact, most entries are empty. Only Claude Opus 4.5 reports results on more than two of the RAI benchmarks, and only GPT-5.2 reports StrongREJECT.
This does not necessarily mean that frontier labs are ignoring RAI, as they do conduct internal evaluations, red-teaming, and alignment testing. However, these efforts are rarely disclosed using a common, externally comparable set of benchmarks. Chapter 2 shows how a small number of shared capability benchmarks make it straightforward to compare models, verify results independently, and track progress over time. However, that kind of comparison has not yet become common practice for RAI evaluation. (View Highlight)
KaBLE is a new benchmark designed to test whether language models can distinguish between what is known and what is merely believed (technically called epistemic reliability). The distinction between knowledge and belief is important in practice. For example, a model used to support a medical diagnosis based on a patient’s mistaken belief, as opposed to an established fact, could reinforce an inaccurate diagnosis and treatment plan. In a legal setting, a model summarizing testimony that cannot tell the difference between what a witness believes and what is known could misrepresent evidence. (View Highlight)
Surveyed organizations reported an increase in the number of AI-related incidents, and their confidence in handling those incidents has dropped. The share of organizations reporting AI incidents remained steady at 8% in both 2024 and 2025 (Figure 3.3.2). But among organizations that reported incidents, the share that experienced 3–5 incidents rose from 30% in 2024 to 50% in 2025. Similarly, in 2024, 42% reported just 1–2 incidents, but that figure fell to 29% in 2025 (Figure 3.3.3).
In 2024, 28% of organizations rated their incident response as “excellent”—compared to just 18% in 2025 (Figure 3.3.4). Those that self-rated their responses as “good” also dropped, from 39% to 24%. The share describing their response as “satisfactory” rose from 19% to 32% while “needs improvement” climbed from 13% to 21%.
Concerns over AI incidents mounted alongside risk awareness (Figure 3.3.5). From 2024 to 2025, the share of respondents who considered inaccuracy a relevant risk rose from 60% to 74%, an increase of 14 percentage points. Cybersecurity rose from 66% to 72%. Active mitigation efforts also increased, with 71% of organizations reporting they actively mitigate inaccuracy risks and 61% mitigating cybersecurity risks. (View Highlight)
AI Governance and Investment
Organizations are formalizing who is responsible for AI governance. Between 2024 and 2025, companies shifted AI governance ownership away from data and analytics functions (down from 17% to 13%), toward dedicated AI governance roles (up from 14% to 17%) (Figure 3.3.6). Information security remained the most common primary owner at 21%, and 5% of organizations reported having no designated owner in 2025 compared to 9% in 2024.
Organizations are also backing their governance structures with financial commitments, though investment levels vary by company size (Figure 3.3.7). Most organizations with under 1billioninrevenuereportedtheyexpectedtoinvestunder5 million in operationalizing RAI, through initiatives such as hiring specialized professions, building or purchasing technical systems, and engaging legal services. At the largest companies, reported investment numbers were significantly higher. Among organizations with at least 30billioninrevenue,4125 million or more and 22% budgeted $50 million or more. (View Highlight)
Implementation, Barriers, and Benefits
Alongside increased accountability structures for responsible AI governance, more organizations have adopted RAI policies. The share that reported not having any policies dropped from 24% in 2024 to 11% in 2025 (Figure 3.3.8). With the uptick in adoption, survey respondents perceived an overall positive impact from RAI policies. Compared to 2024, more organizations reported that RAI policies improved business outcomes (up 7 percentage points), business operations (up 4 percentage points), and customer trust (up 4 percentage points). Furthermore, more organizations reported a drop in the number of AI incidents (plus 8 pp).
Knowledge and training gaps remain the top-cited obstacle to implementing responsible AI, rising from 51% in 2024 to 59% in 2025 (Figure 3.3.9). The second sharpest increase was in technical limitations, with 38% of respondents citing them as a main obstacle, up from 32% in 2024. Resource constraints and regulatory uncertainty continued to rank among the top barriers.
However, the barriers to scaling agentic AI systems followed a different order (Figure 3.3.10). Security and risk concerns far outweighed the others, with 62% of respondents naming these as the primary obstacle, followed by technical limitations (38%) and regulatory uncertainty (38%). Lack of executive support was reported as a greater barrier to implementing RAI policies (14%) than with agentic AI (9%). (View Highlight)
Global corporate AI investment more than doubled in 2025. Private investment grew fastest at 127.5% and now accounts for 60% of the total. Generative AI led the surge, growing more than 200% and capturing nearly half of all private AI funding. Newly funded AI companies rose 71%, and billion-dollar funding events nearly doubled. (View Highlight)
The United States continues to lead in global private AI investment, committing 23 times more than China. In generative AI, U.S. investment exceeded the combined total of China and Europe by a wide margin. However, private investment figures likely understate China’s total AI spending, as government guidance funds have deployed an estimated $184 billion into AI firms between 2000 and 2023. (View Highlight)
AI company revenue is rising at historically fast rates, but compute costs and infrastructure spending are also reaching record levels. Leading frontier companies are reaching meaningful revenue scale in a short period of time, but compute spend has increased significantly year-overyear. Major cloud providers have accelerated capital expenditures, with Google reporting more than $150 billion in annual capex in 2025. (View Highlight)
The value consumers get from generative AI grew 54% in a year. Estimated U.S. consumer surplus reached 172billionannuallybyearly2026,upfrom112 billion a year earlier, with the median value per user tripling over the same period. Most of these tools remain free or close to it. (View Highlight)
Organizational AI adoption continued to rise in 2025, up to 88% of surveyed organizations, though AI agent use remains early. Generative AI is now used in at least one business function at 70% of organizations, and China and Europe posted the highest year-over-year increases. AI agent deployment was in the single digits across nearly all business functions. (View Highlight)
Generative AI reached 53% adoption in three years, faster than the personal computer or the internet. Adoption varies widely across countries and correlates strongly with GDP per capita, though some outpace what income would predict, including Singapore at 61% and the United Arab Emirates at 54%. Despite its lead in AI investment and model development, the United States ranks 24th at 28.3%.` (View Highlight)
AI’s labor market effects are showing up unevenly, concentrated in hiring pipelines and the youngest workers in exposed occupations. Employment for software developers ages 22 to 25 has fallen nearly 20% from 2024. Employer surveys point to further change ahead, with onethird of respondents expecting workforce reductions over the coming year. (View Highlight)
One-third of organizations expect AI to reduce their workforce in the coming year, even though large-scale job losses have not yet shown up in overall employment data. Almost half of organizations surveyed expected little to no change. Anticipated reductions are highest in service operations, supply chain, and software engineering. Across nearly all functions, anticipated decreases outpaces those already observed. (View Highlight)

 (View Highlight)
(View Highlight)
 (View Highlight)
(View Highlight)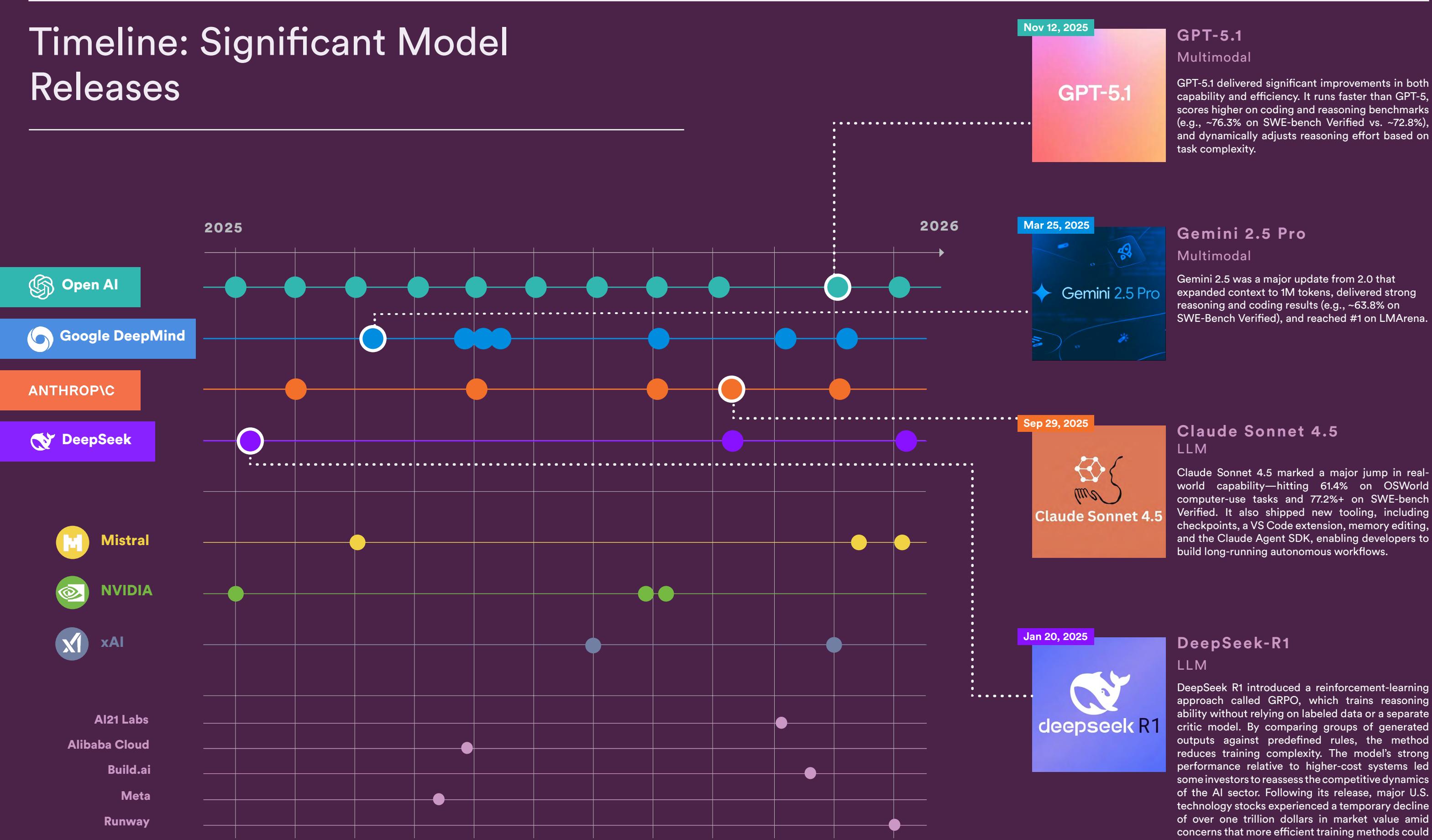 (View Highlight)
(View Highlight)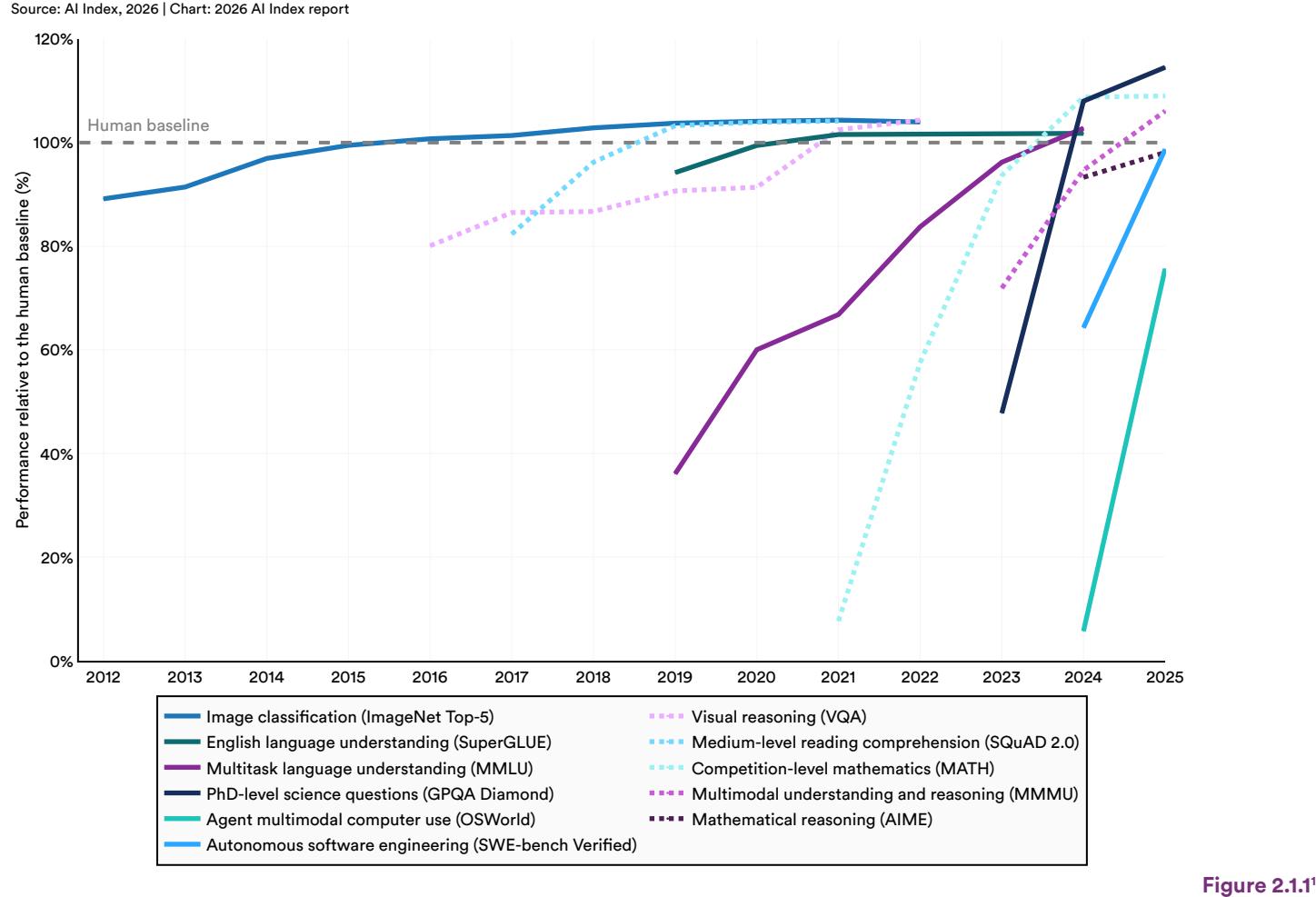 (View Highlight)
(View Highlight)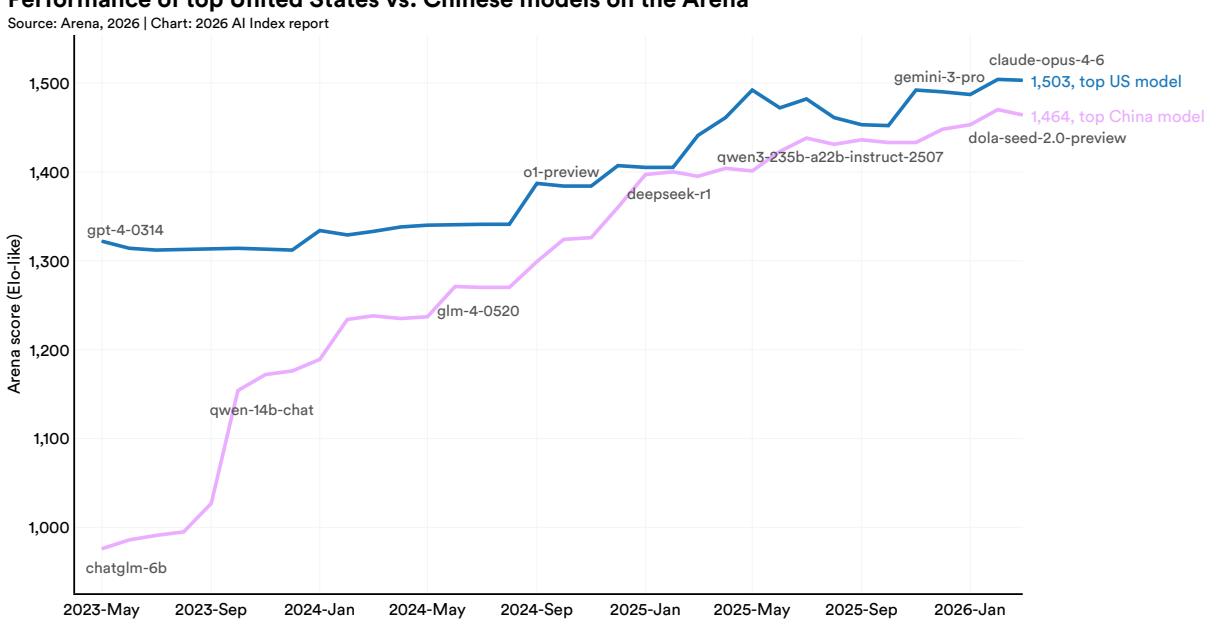 (View Highlight)
(View Highlight)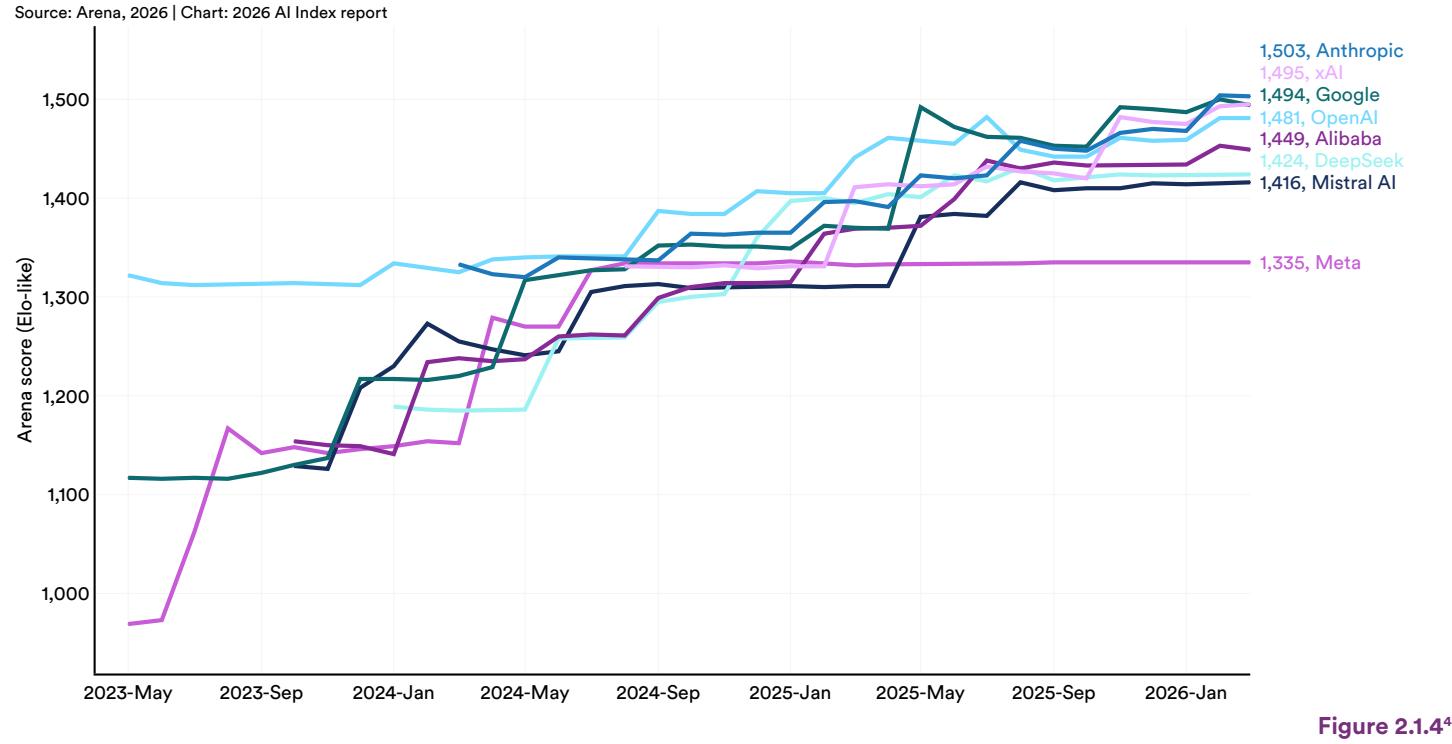 (View Highlight)
(View Highlight)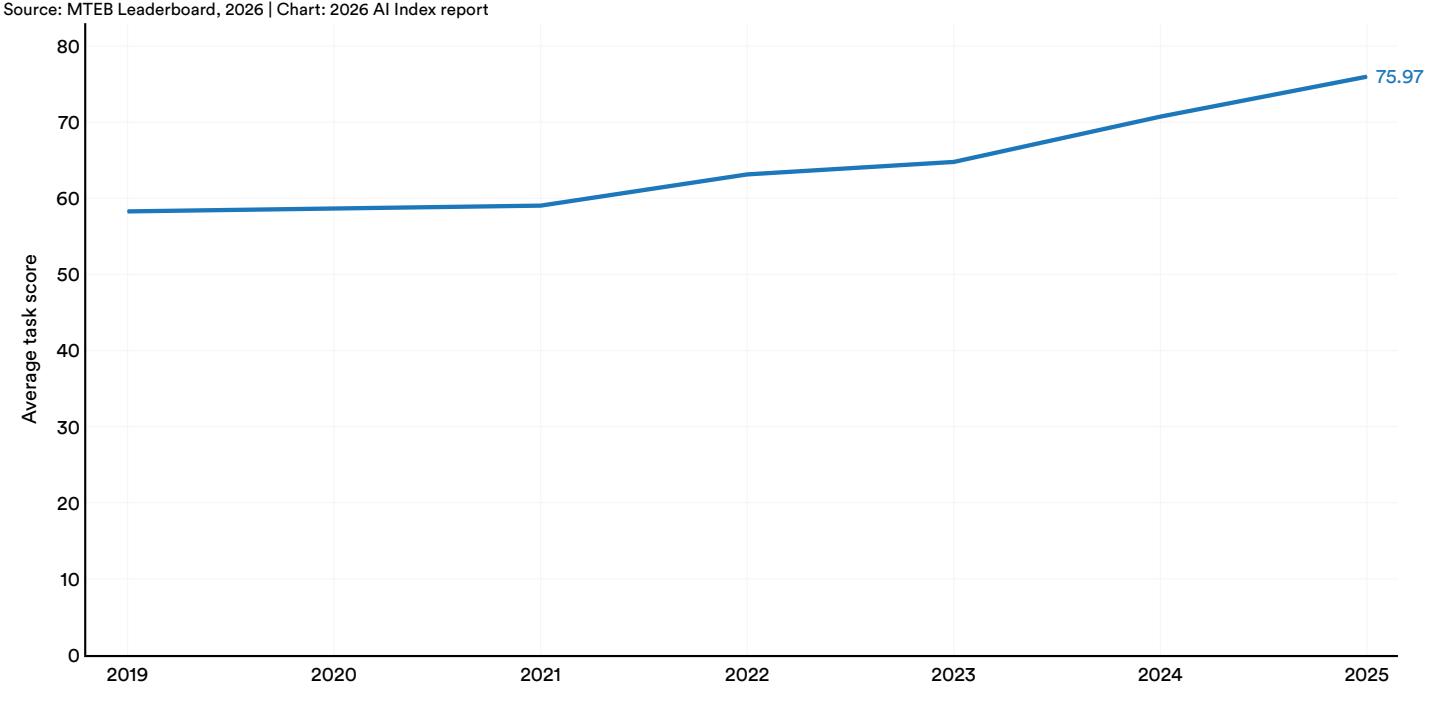 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)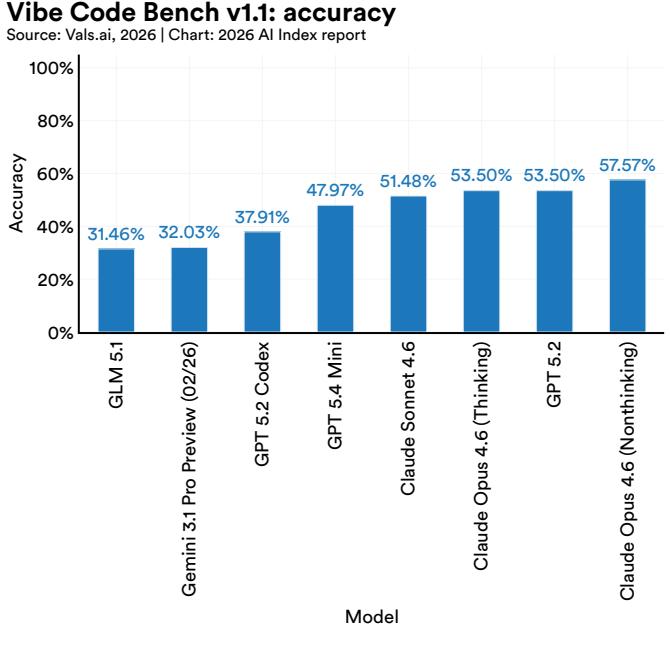 (View Highlight)
(View Highlight)