The Anthropic Economic Index uses our privacy-preserving data analysis system to track how Claude is being used across the economy. It’s part of our effort to understand the economic impacts of AI as early as possible, so that researchers and policymakers have adequate time to prepare.
This latest report studies Claude usage in February 2026, building on the economic primitives framework introduced in our previous report (which used data from November 2025). Our sample covers February 5 to February 12, three months following the release of Claude Opus 4.5 and coincident with the release of Claude Opus 4.6. (View Highlight)
We first document how usage has changed relative to our previous reports: the rate of augmentation, collaborative interaction where the AI complements the user’s abilities, increased slightly in both Claude.ai and API traffic. In Claude.ai, usage diversified, with the top 10 tasks accounting for a smaller share of usage last month than in November 2025. As a result of this diversification, the average conversation in Claude.ai had a slightly lower-wage task than in previous reports. (View Highlight)
We then focus on an important determinant of Claude’s impact on the labor market and the broader economy: learning curves in Claude adoption. We present evidence that high-tenure users have developed habits and strategies that allow them to better harness Claude’s capabilities. Indeed, we document that more experienced users not only attempt higher-value tasks, but are also more likely to elicit successful responses in their conversations. (View Highlight)
Claude adoption broadened to lower-wage tasks. As use cases have diversified, the average economic value of work done on Claude—as measured by US wages paid to workers in the associated occupations—has decreased slightly. This is caused, mechanically, by a rise in personal queries around sports, product comparisons, and home maintenance. The pattern is consistent with a standard “adoption curve” story, in which early-adopters favor specific high-value uses like coding, and later adopters take on a much wider range of tasks. (View Highlight)
Inequality in global usage has persisted. Usage remains heavily concentrated: the top 20 countries account for 48% of all per-capita usage, up from 45%, underscoring a persistent gap in global adoption. However, Claude usage per capita continued to converge within the United States: the share of usage accounted for by the 10 highest usage states decreased from 40% to 38% since our last report. (View Highlight)
A central finding in the Economic Index is that early adoption of Claude is very uneven: Claude is used more intensely in high-income countries, within the US in places with more knowledge workers, and for a relatively small set of specialized tasks and occupations.
An important question is how inequality of adoption might determine where and to whom the benefits of AI will accrue. If, for example, effective AI use requires complementary skills and expertise—which we argued in our previous report—and if such skills can be acquired through use and experimentation, then the benefits from early adoption may be self-reinforcing. (View Highlight)
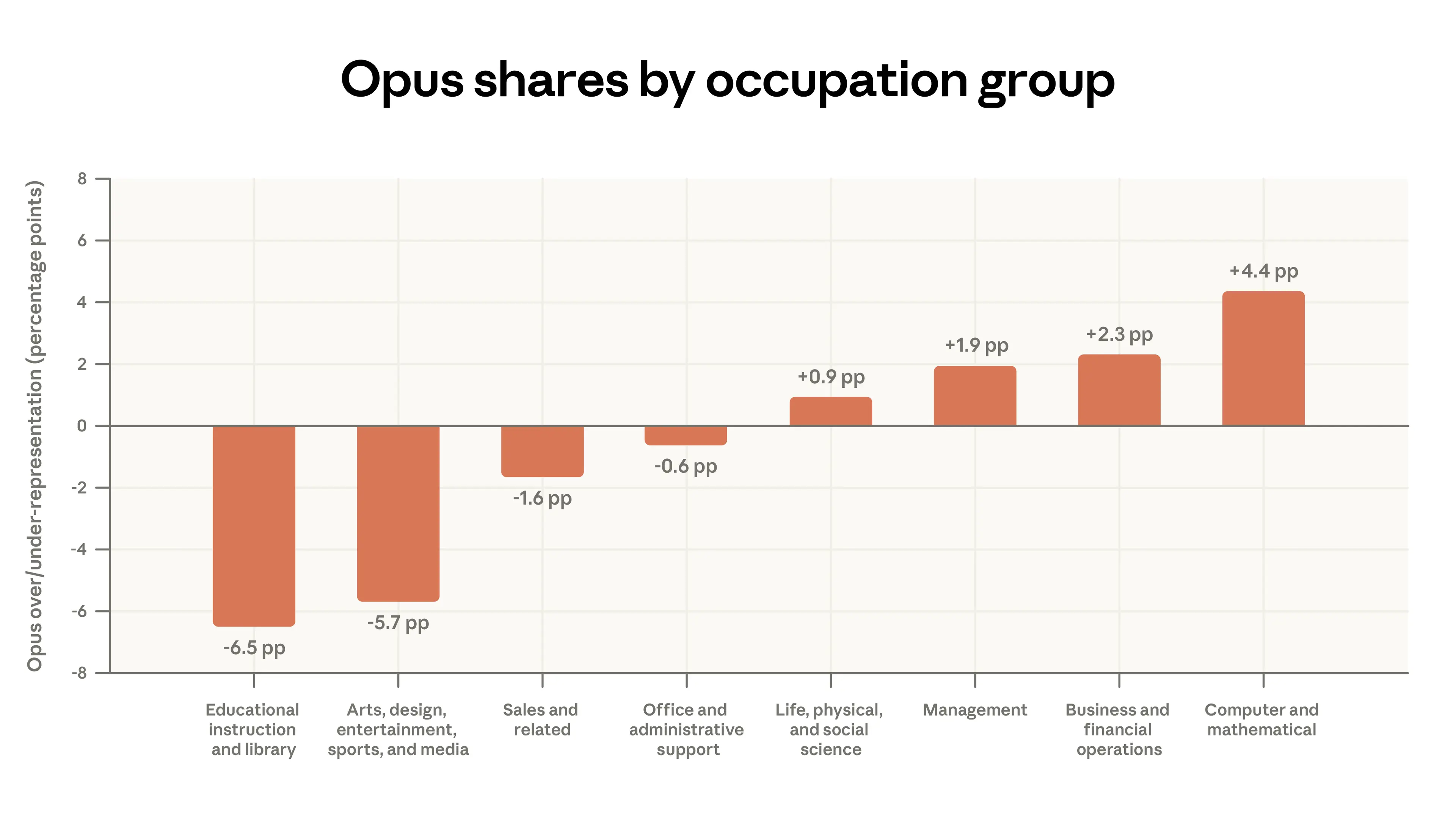
Model selection matches the task. We show that users choose our most intelligent model class, Opus, for tasks that normally receive higher wages in the labor market. For example, among paying Claude.ai users, Opus is used 4 percentage points more than average for coding tasks and 7 percentage points less than average for tutoring-related tasks. This model switching is about twice as stark for API users. (View Highlight)
Higher tenure, higher success. In general, the most seasoned Claude users employ it more often for higher-education tasks and less often for personal use cases. For example, people who have been using Claude for 6 months or more have 10% fewer personal conversations and a 6% higher education level reflected in their inputs. Most strikingly, people in this higher-tenure group have a 10% higher success rate in their conversations, an association that is not explained by their task selection, country of origin, or other factors. While this could reflect sophistication of early adopters, it could also be evidence of learning-by-doing, where people get better at using Claude through experience. (View Highlight)
We first look at the kinds of tasks that Claude is asked to perform. We use our privacy-preserving system, which allows us to describe behavior at an aggregated level without revealing the content of individual transcripts. We sample 1 million conversations from both Claude.ai, our consumer-facing web product, and our first-party API, the developer-facing interface for integrating Claude into products and workflows.2
Coding remains the most common use on our platforms, with tasks associated with Computer and Mathematical occupations accounting for 35% of conversations on Claude.ai (see Appendix).3 However, between November 2025 and February 2026, use cases on Claude.ai became less concentrated: the top 10 most common O*NET tasks went from 24% of conversations to just 19% (Figure 1.1). (View Highlight)
This migration of code out of Claude.ai is not the only factor driving decreased concentration. Part of the drop is due to changes in the mix of use cases between the two periods. Coursework fell from 19% to 12% of conversations, while personal use rose from 35% to 42% of conversations. Some of the drop in coursework can be explained by academic calendars in countries where students were on winter break during our sample period.4 At the same time, increasing signups beginning around February brought more casual AI users. (View Highlight)
As tasks migrate to the API, they may become more exposed to automation. API workflows are far more likely to be directive, with less need for a human in the loop. In a previous report, we highlighted that customer service tasks, including, for example, automated support for payment and billing issues, are prevalent in the API data. These contributed to a higher observed exposure for Customer Service Representatives—Claude was recorded doing a high share of their tasks in automated workflows, so these jobs may be more likely to change as AI diffuses.
We highlight two API workflows that appeared more frequently in February as compared to three months prior, with their shares at least doubling in our latest sample:7
• Business sales & outreach automation: sales enablement generation, B2B lead qualification research, customer data enrichment, cold-email drafting.
• Automated trading & market ops: monitor markets or positions, propose specific investments, inform traders of market conditions, and related tasks. (View Highlight)
First, we shed light on the demand for intelligence by studying when people choose Opus, our most performant model class. Little is known about how AI users choose between different models, navigating tradeoffs around speed, performance, and cost. If users are calibrating to the task at hand, we should see Opus concentrated on harder, higher-value work.
Next, we study how usage differs according to tenure, finding differences across users who signed up at different times. This sheds light on learning curves: do experienced users get better over time? How does their usage differ? We find evidence consistent with learning-by-doing. Not only do higher-tenure users have greater success in their conversations, they also collaborate with Claude more, bring more challenging tasks to Claude, and are more likely to use Claude for work purposes and for a wider range of tasks. (View Highlight)
The different Claude model classes (Haiku, Sonnet, and Opus) offer tradeoffs in terms of cost, speed, and performance. The Opus class of models uses the most tokens and excels at complex tasks, but at a higher per-token price on our API. If users are aware of this and mindful of costs and usage limits, they should bring their most complicated and valuable tasks to Opus, while selecting other models for simpler tasks. This is broadly what we observe in the data.
Figure 2.1 below shows that, for paid Claude.ai accounts, which have access to all model classes, 55% of Computer and Mathematical tasks (like coding software) use Opus, compared to 45% of Educational tasks. Technical users may notice performance gains and actively switch away from Sonnet, the default. Or efficiency-minded users may learn to use Sonnet for simpler tasks to avoid hitting usage limits. Relatedly, the differences here could reflect that most educational tasks are already fairly easy for Sonnet, or that students are more likely to be mindful of usage limits.
(View Highlight)
Table 2.1 shows differences between low tenure and high tenure users, where the latter group is defined as having signed up for Claude at least 6 months ago and the low tenure users are everyone else.10 High tenure users are more likely to use Claude to iterate on their work, and much less likely to delegate greater responsibility through directive use patterns. They are 7 percentage points more likely to be using Claude for work, and use Claude for tasks that tend to require higher levels of education. Finally, their usage is less concentrated in certain tasks. The top 10 O*NET tasks account for a slightly lower (20.7% compared to 22.2%) share of usage for the high tenure group.
(View Highlight)
Below, we dig more into two of the primitives discussed above: the human years of schooling associated with each conversation, and the share of transcripts devoted to personal use.
In the panel on the left, we show that the years of schooling needed to understand the human prompt increases by almost 1 year for every additional year of Claude usage. In the panel on the right, we show that at the same time, personal use decreases: people who signed up a year ago devote 38% of their conversations to personal use cases, compared to 44% for the newest users.
(View Highlight)
We explore these relationships more in Figure 2.4 below, using the log-level data to control granularly for features of the conversation. In the top panel, specification (1) shows a simple bivariate regression with task success as the outcome and the long-tenure indicator as the predictor. Success is Claude’s assessment of whether the conversation was successful, described in our previous report. The plot shows that long-tenure users are about 5 percentage points more likely to have a successful conversation.
This could reflect that higher-tenure users are better at prompting. But what if it reflects that they bring different tasks to Claude—ones more likely to be successful?
In Specification (2), we include fixed effects for specific O*NET tasks and request clusters. This amounts to comparing high- and low-tenure users within the same narrowly defined task, rather than across tasks. For instance, we have a request cluster called “Perform corporate financial analysis, valuation, and modeling for specific companies.” The fixed effects compare high- and low-tenure users within that cluster, and likewise within every other cluster. We would only observe a positive coefficient if, on average, long-tenure users are more successful in these within-task comparisons. This control moderates the effect somewhat, bringing it closer to 3 percentage points.
(View Highlight)
Overall, Claude is used for high-value, complex work that is not broadly representative of the US economy. But as the user base has grown, less remunerated tasks have become a slightly larger share of traffic. The average value of tasks, measured as the estimated wage paid to workers in occupations associated with those tasks, has declined on Claude.ai since our first report, while rising among API users. On both surfaces, users bring their most complex tasks to our more powerful model class, Opus. This inflection is stronger for API customers. (View Highlight)
More experienced users tend to use Claude more collaboratively, for more work-related reasons, in more complex tasks, and with more success. This pushes back against a hypothesis we made last year that automated use may be more typical of more experienced, sophisticated users; instead, we find that the most advanced users are more likely to iterate with Claude. It’s also consistent with learning-by-doing: the more time one spends using AI, the more effective one becomes at harnessing it. (View Highlight)
 (View Highlight)
(View Highlight)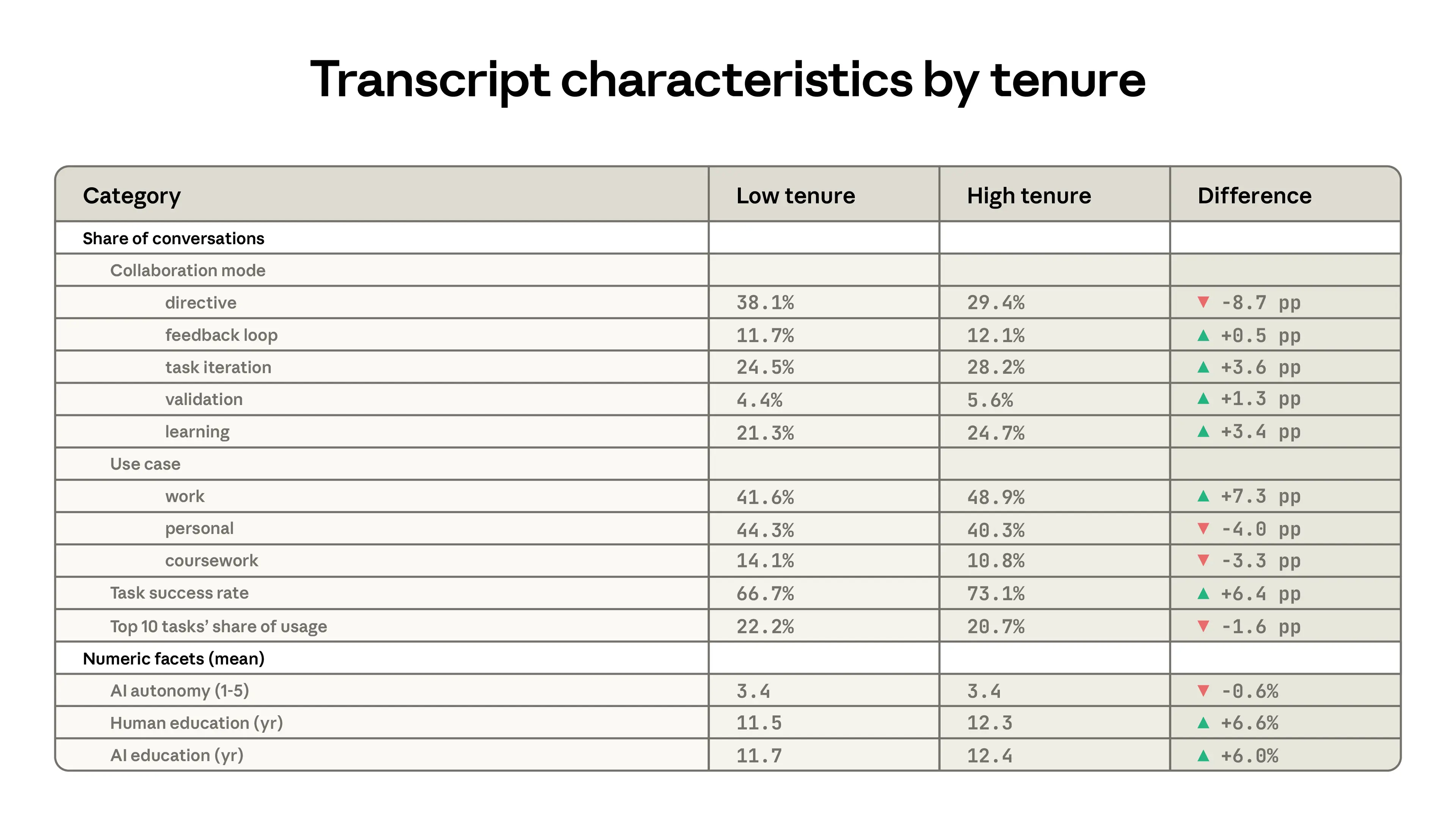 (View Highlight)
(View Highlight)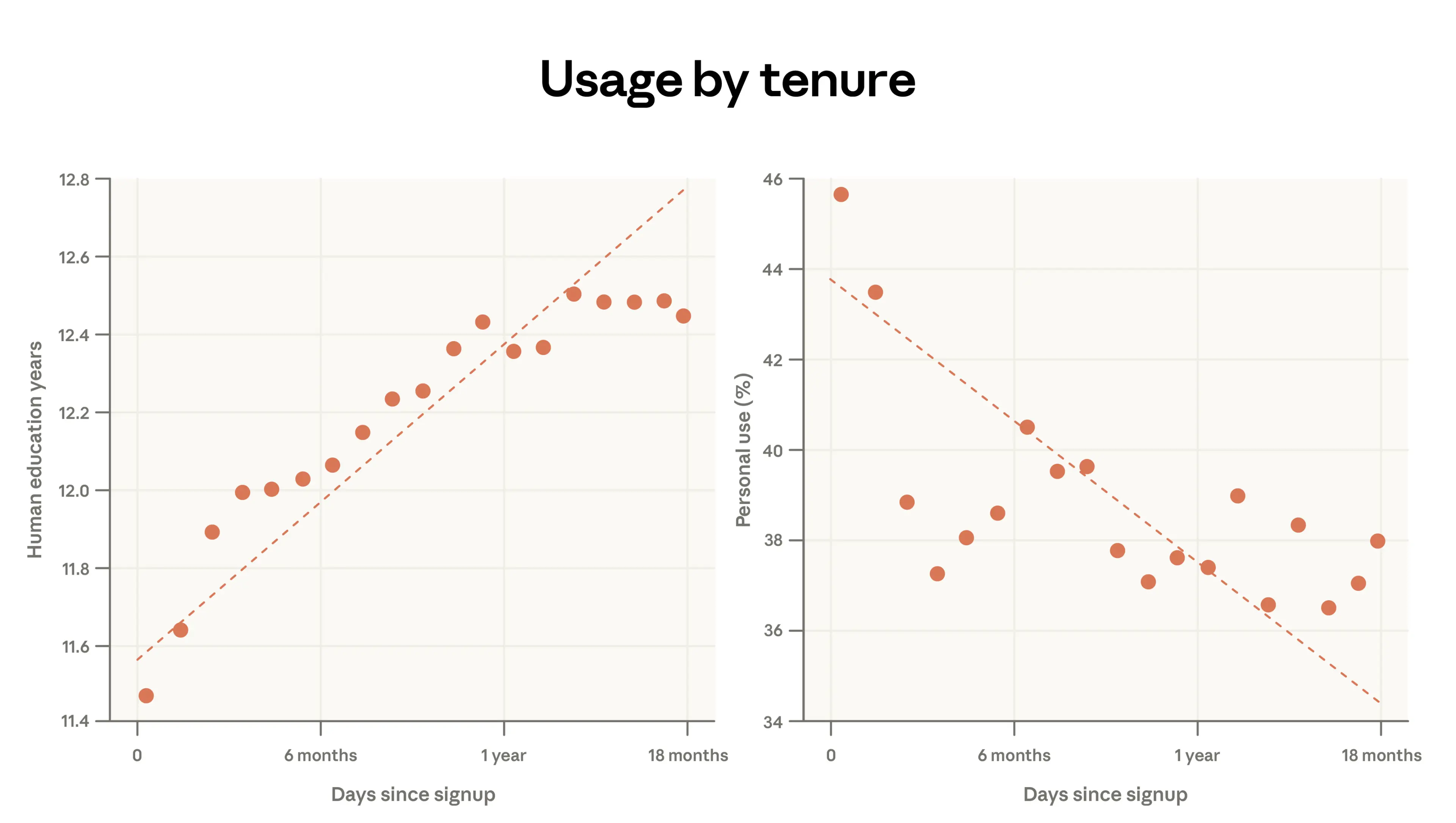 (View Highlight)
(View Highlight)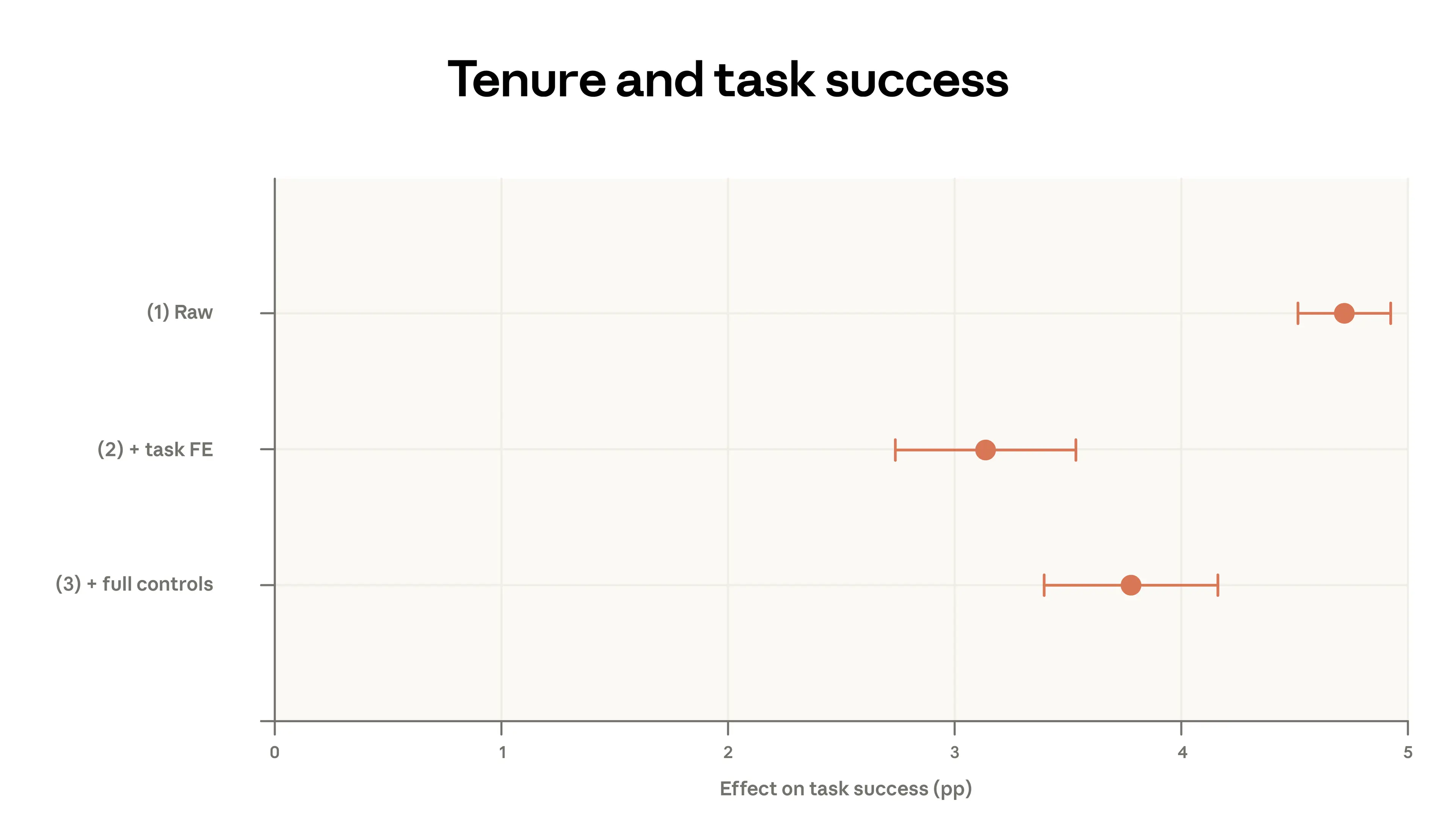 (View Highlight)
(View Highlight)