utomated valuation model, is the name given to a Machine Learning model that estimates the value of a property, usually by comparing that property to similar nearby properties that have recently sold (comparables or comps). Comps are key: an AVM evaluates a property relative to its comps, assimilating those data into a single number quantifying the property’s value. (View Highlight)
Many companies have an “AI strategy,” but at Opendoor (scare quotes) “AI” is the business. We don’t buy or sell a single home without consulting OVM — for a valuation, for information regarding comparable properties, or for both. (View Highlight)
OVM (handcrafted model pipeline)
Select comps
Score said comps based on their “closeness” to the subject property
“Weight” each comp relative to the others
“Adjust” the (observed) prices of each comp
Estimate “uncertainty” via multiple additional models (View Highlight)
or our purposes, the ability to define an end-to-end system, in which gradients flow freely through all aspects of the valuation process, is key: for instance, attempting to assign weights to comps without also considering the requisite adjustments (a shortcoming of the prior algorithm) leaves useful information on the table. This shortcoming was top-of-mind as we built out our current framework. (View Highlight)
OVM (deep learning)
Select comps
Give everything to a neural net and hope it works!
(View Highlight)
In residential real estate, we know the causal mechanism by which homes are valued, a powerful backstop typically unavailable in computer vision or Natural Language Processing (NLP) applications. That is, a home is priced by a human real estate agent who consults comps (those same comps again) and defines/adjusts the listing’s price based on:
• the recency of the comps (which factors in home price fluctuations)
• how fancy/new/desirable the comps are relative to the subject property (View Highlight)
Comp prices are more than correlative: a nearby comp selling for more than its intrinsic value literally causes one’s home to be worth more, as no shopper will be able to perfectly parse the underlying “intrinsic value” from the “noise (error)” of previous home sales. This overvaluation propagates causally into the future prices of other nearby homes. (View Highlight)
Deep learning, through categorical feature embeddings, unlocks an extremely powerful treatment of high-cardinality categorical variables that is ill-approximated by ML stalwarts like linear models and Gradient Boosted Trees. (View Highlight)
Real estate has surprising similarities to NLP: high-cardinality features such as postal code, census block, school district, etc. are nearly as central to home valuations as words are to language. By providing access to best-in-class handling of categorical features, a deep learning based solution immediately resolved a primary flaw of our system. Better yet, we didn’t need to lift a finger, as embedding layers are a provided building-block in all modern deep learning frameworks. (View Highlight)
The final unresolved defect of our prior algorithm was its inability to jointly optimize parameters across sub-model boundaries. For instance, the model that assigned comp weights did not “talk” to the model that predicted the dollar-value of the comp-adjustment that would bring said comp to parity with the subject listing. (View Highlight)
PyTorch, cleanly resolves this fault, as well. We can define sub-modules of our network to tackle the adjustment and weighting schemes for each comp, and autograd will handle backward-pass gradient propagation within and between the sub-modules of the net. (View Highlight)
There are several approaches to model this process (while enabling joint-optimization). We’ve had success with many model paradigms presently popular in NLP and/or image retrieval / visual search. (View Highlight)
• Transformer-style network architectures that accept a variable-length sequence of feature vectors (perhaps words or houses) and emit a sequence or single number quantifying an output
• Siamese Networks that compare, for example, images or home listings and produce a number/vector quantifying the similarity between any two of them
• Triplet loss frameworks for similarity detection (and, more recently, contrastive-loss approaches spiritually similar to triplet loss)
• Embedding lookup schemes such as Locality Sensitive Hashing that efficiently search a vector-space for similar entities to a query-vector of interest (View Highlight)
The process of valuing a home is similar to NLP for one key reason: a home “lives” in a neighborhood just as a word “lives” in a sentence. Using the local context to understand a word works well; it is intuitive that a comparable method could succeed in real estate. (View Highlight)
Image retrieval hinges on querying a massive database for images similar to the query image — a process quite aligned with the comparable-listing selection process.
Which model works best will depend on the specifics of the issue one is trying to solve. Building a world-class AVM involves geographical nuance as well: an ensemble of models stratified by region and/or urban/suburban/exurban localization may leverage many or all of the above methodologies. (View Highlight)
With our network(s) we must be able to answer two key questions:
How much more (or less) expensive is some comp listing than the listing of interest?
How much weight (if any) should be assigned to said comp, relative to the other comps? (View Highlight)
The module might take in tabular data (about the listing’s features), photos, satellite imagery, text, etc. It may also use contextual information, including information about the other comps available for the given listing of interest — a transformer’s self-attention aligns well with this notion of contextual info. (View Highlight)
• An estimate of the relative price difference between a given (subject, comp) listing pair
• A “logit” (un-normalized weight) characterizing the relative strength of a comp (View Highlight)
Because the comp weights should sum to one, a normalization scheme (perhaps softmax, sparsemax, or a learned reduction-function) is employed after the weights are computed. Recall that the comparable properties have already recently sold (never mind active listings for now), so their close prices are known. That close price, augmented by the price delta computed in (1), is itself a powerful predictor of the close price of the subject listing. (View Highlight)
These transformer-based techniques from NLP work well because each comp can be viewed as a draw from a relatively homogeneous bag of possible comparable properties. In this capacity, comps are quite similar to words in the context of a language model: atomic units that together form a “sentence” that describes the subject listing and speculates regarding its worth.
Though, deciding which words (comps) to place in that sentence is a tricky problem in its own right. (View Highlight)
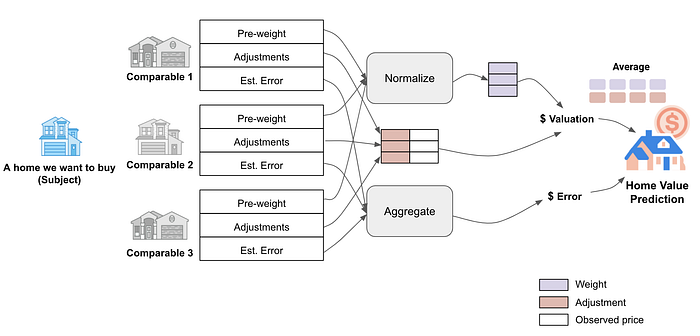
Once the aforementioned quantities are in hand, the valuation process reduces immediately to a standard regression problem:
The observed comp close prices are adjusted via the values proposed by our network
These adjusted close prices are reduced, via a weighted-average-like procedure, to a point estimate of the subject’s close price
Your favorite regression loss can then be employed, as usual, to train the model and learn the parameters of the network (View Highlight)
We saw a step function improvement in accuracy after implementing these ideas; the bulk of the improvement can be attributed to (1) end-to-end learning and (2) efficient embeddings of high-cardinality categorical features. (View Highlight)
Humans interact (and fall in love) with homes through photos. It seems natural, then, that a deep learning model would leverage these images when comparing homes to one another during the appraisal process. After all, one of the great success stories of deep learning is the field of computer vision. Transitioning OVM to deep learning has the added benefit of making it much easier to incorporate mixed-media data, such as images and text (from listings, tax documents, etc.) into our core algorithm. (View Highlight)
 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)