For years, developer productivity has improved through better tooling. We have smarter IDEs, faster builds, better tests, and more reliable deployments. But even so, maintaining a codebase, keeping dependencies up to date, and ensuring that the code follows best practices demands a surprising amount of manual work. At Spotify, our Fleet Management system automated much of that toil, yet any moderately complex migration still requires many human hands. (View Highlight)
This post explores how we have evolved our Fleet Management platform with background coding agents and what more than 1,500 merged AI-generated pull requests have taught us about the future of large-scale software maintenance. (View Highlight)
Fleet Management is a powerful framework for applying code transformations across all of Spotify’s repositories. The idea is simple: We write small snippets of code that themselves modify source code and apply these transformations to thousands of software components. This way we can take care of maintenance tasks across our codebase. (View Highlight)
On a high level, Fleet Management has been a roaring success. It has allowed us to automate away countless hours of toil, vastly reducing the time to roll out fleet-wide changes. The system works by running these source-to-source transformations as jobs, in a containerized environment, which then automatically open pull requests against the target repositories. (View Highlight)
But we knew from the beginning that this approach has its limits. While it is great for simple, repeatable tasks, making complexcode changes is a challenge we’ve never fully solved. Defining source code transformations programmatically, by manipulating a program’s abstract syntax tree (AST) or using regular expressions, requires a high degree of specialized expertise. One example is our automated Maven dependency updater. While its core function — identifying pom.xml files and updating Java dependencies — is straightforward, handling all corner cases has led to the transformation script growing to over 20,000 lines of code. Because of this complexity, most of the automated changes we could implement were simple ones. Only a few teams have the required expertise and time to implement more sophisticated Fleetshifts over our entire codebase. (View Highlight)
At the same time, AI tools are becoming much more capable of making complex code changes. This presented a clear and promising opportunity: (View Highlight)
We started with the part of the process that needed the most help: the declaration of the code transformation itself. We replaced deterministic migration scripts with an agent that takes instructions from a prompt. All the surrounding Fleet Management infrastructure — targeting repositories, opening pull requests, getting reviews, and merging into production — remains exactly the same. (View Highlight)
Instead of adopting an off-the-shelf coding agent as it is, we decided to build a small internal CLI. This CLI can delegate executing a prompt to an agent, run custom formatting and linting tasks using local Model Context Protocol (MCP), evaluate a diff using LLMs as a judge, upload logs to Google Cloud Platform (GCP), and capture traces in MLflow. Crucially, having that CLI allows us to seamlessly switch between different agents and LLMs. In the fast-moving environment that is GenAI, being flexible and pluggable this way has already allowed us to swap out pieces multiple times, giving our users a preconfigured and well-integrated tool out of the box, without exposing them to the nitty-gritty details. (View Highlight)
We quickly found enthusiastic users for this feature, for example, as a lightweight way for engineers to capture architecture decision records (ADRs) from a thread in Slack, or product managers that can now propose simple changes without cloning and building repos on their laptops. (View Highlight)
This approach has excelled in several areas, including:
• Bumping dependencies in build files, such as in a Maven Project Object Model (POM) files
• Updating configuration files, such as deployment manifests
• Executing simple code refactors, like removing or replacing a deprecated method call (View Highlight)
The impact has been significant, with a steady stream of automated pull requests being merged daily, keeping our codebases consistent, up to date, and secure. Since mid-2024, around half of Spotify’s pull requests have been automated by this system.
(View Highlight)
Last February, we began an investigation into using AI agents within our Fleet Management system. The goal was to allow engineers to define and run fleet-wide changes using natural language.
Figure 3: Integration of coding agents into our Fleet Management architecture. (View Highlight)
We saw an immediate need for this type of product internally. We were codeveloping the tooling alongside early adopters who applied it to their in-flight migrations. To date, our agents have generated more than 1,500 pull requests that teams across Spotify have merged into our production codebase. And not trivial changes, either — we’re now starting to tackle changes such as:
• Language modernization, such as replacing Java value types with records
• Upgrades with breaking changes, such as migrating data pipelines to the newest version of Scio
• Migrating between UI components, such as moving to the new frontend system in Backstage
• Config changes, such as updating parameters in YAML or JSON files and still adhering to schemas and formatting (View Highlight)
By exposing our background coding agent via MCP, Spotifiers can now kick off coding agent tasks from both Slack and GitHub Enterprise. They first talk to an interactive agent that helps to gather information about the task at hand. This interaction results in a prompt that is then handed off to the coding agent, which produces a pull request. (View Highlight)
Introducing AI agents into our migration and developer workflows is a new and exciting space for us. We see great impact and momentum from our first iteration of tools: hundreds of developers now interact with our agent, and we’ve already merged more than 1500 pull requests.
But coding agents come with an interesting set of trade-offs. Performance is a key consideration, as agents can take a long time to produce a result, and their output can be unpredictable. This creates a need for new validation and quality control mechanisms. Beyond performance and predictability, we also have to consider safety and cost. We need robust guardrails and sandboxing to ensure agents operate as intended, all while managing the significant computational expense of running LLMs at scale. (View Highlight)

 (View Highlight)
(View Highlight) (View Highlight)
(View Highlight)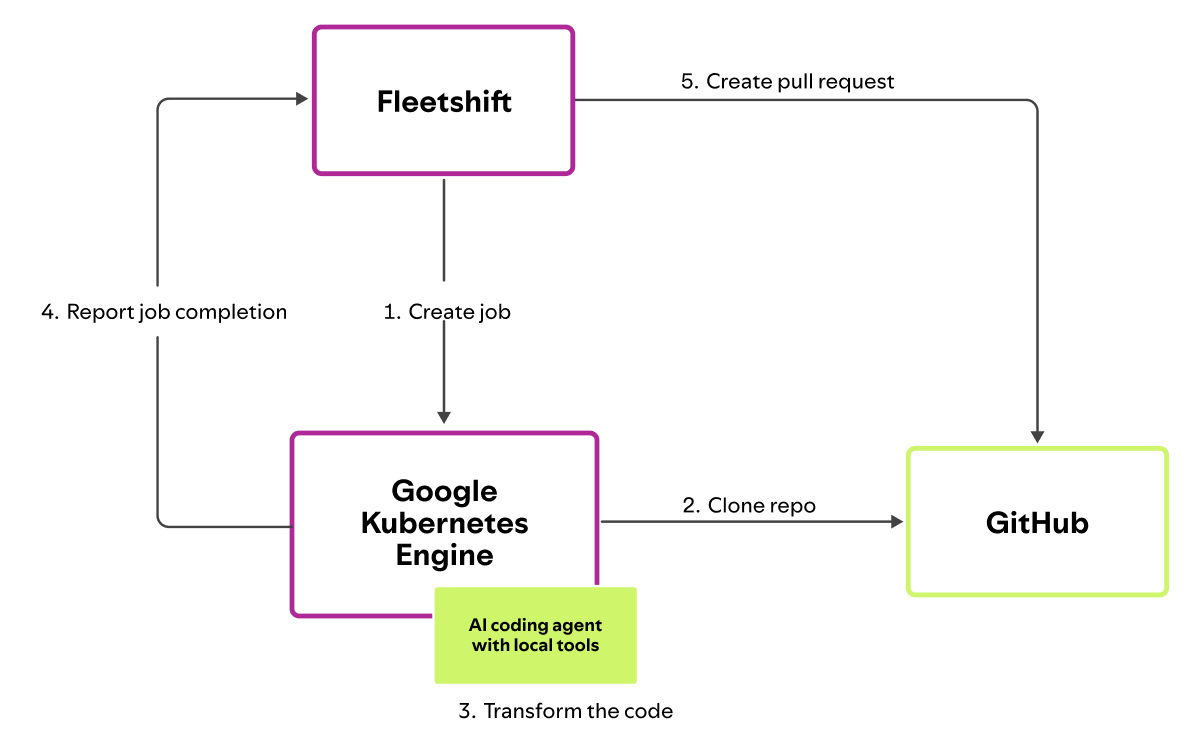 Figure 3: Integration of coding agents into our Fleet Management architecture. (View Highlight)
Figure 3: Integration of coding agents into our Fleet Management architecture. (View Highlight)